Policy Search를 다루는 CS234 Reinforcement Learning 9-10강을 들었습니다.
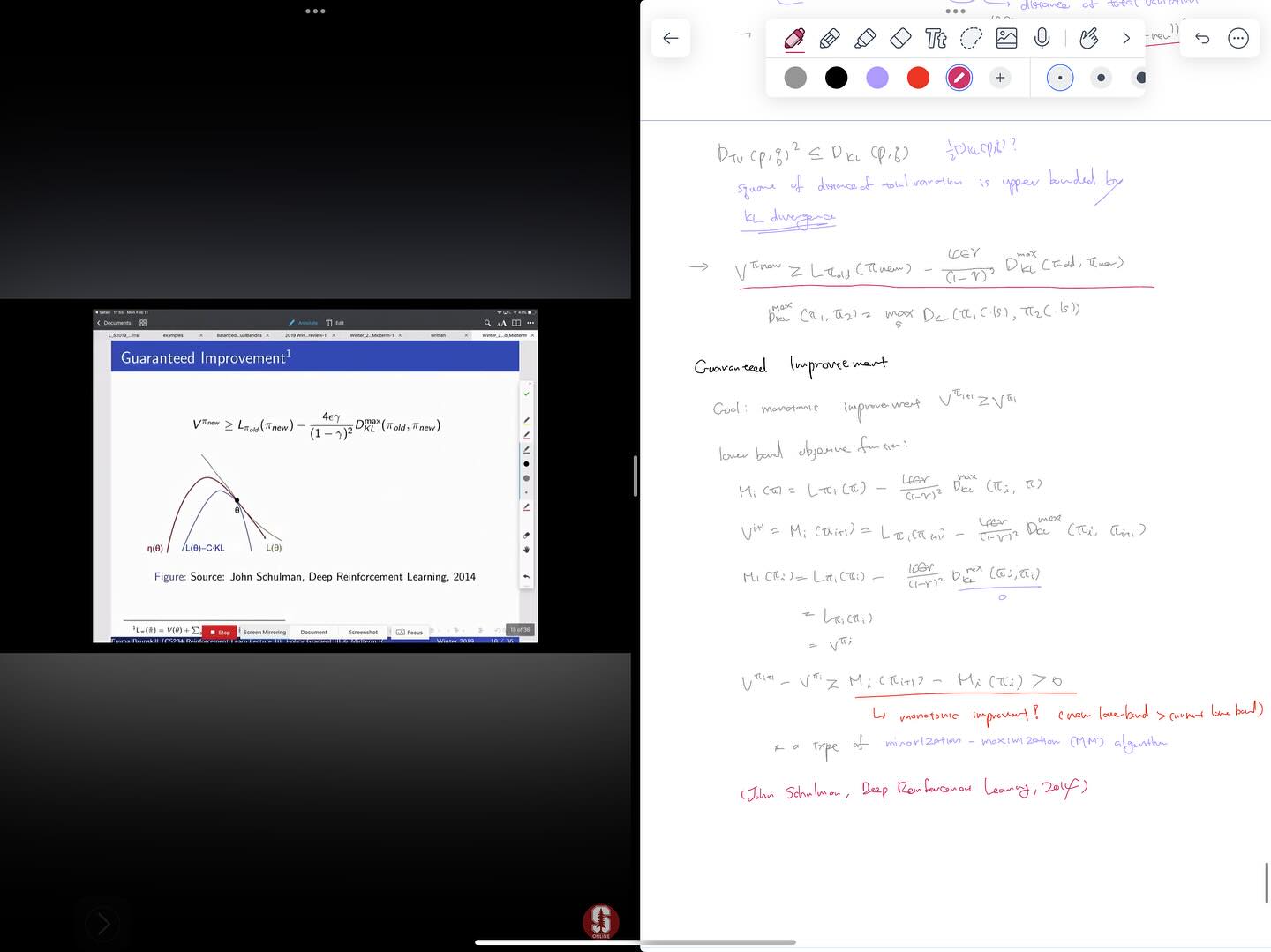
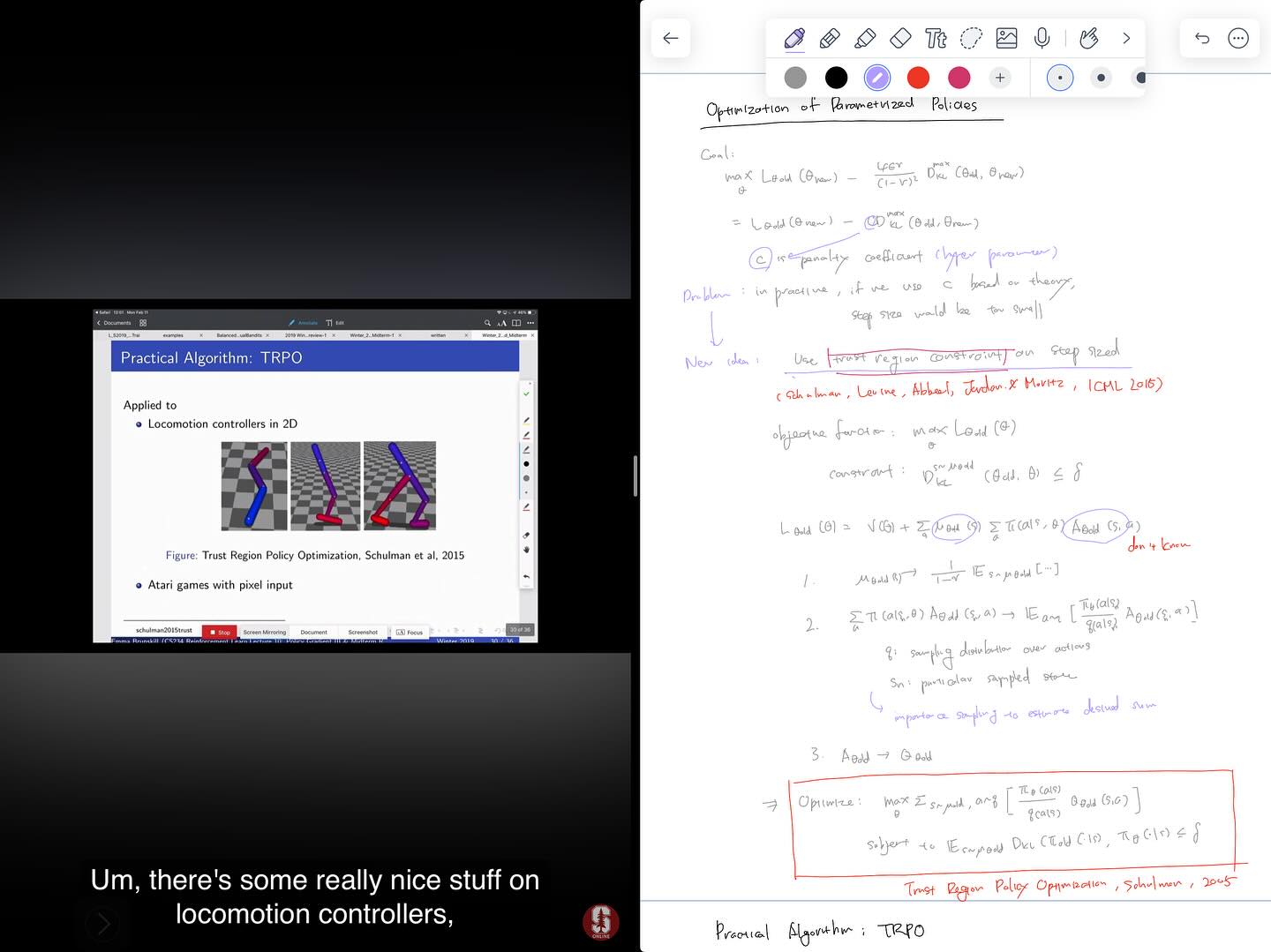
9강은 Sutton Chapter 13에서도 다루고 있는 REINFORCE with baseline에 관한 내용입니다. 10강에서는 이러한 Policy Gradient method에서 monotonic improvement를 보장하기 위해서 step size를 결정하는 문제를 다룹니다. 여기서 매우 유명한 TRPO (Trust Region Policy Optimization) 알고리즘에 이르는 과정을 배우게 됩니다. Policy gradient의 iteration에서 새로운 policy의 value를 알 수는 없지만, lower-bound를 계산할 수 있고, 이러한 lower-bound가 개선되는 것을 보장할 수 있는 objective function과 constraint를 제안합니다. 이를 통해서 policy value를 최대화하면서 안정적인 학습이 이루어질 수 있도록 step size를 결정하는 알고리즘이 TRPO 알고리즘입니다.
계산이 어려운 문제를 계산 가능한 문제로 전환하고 이로부터 실용적인 알고리즘을 제안하는 과정이 ‘아름답다’고 밖에는 말할 수 없는 흥미로운 토픽이었습니다.