Reinforcement Learning 7, 8강을 들었습니다. 각각 Imitation Learning과 Policy Search의 도입부를 다루고 있습니다.
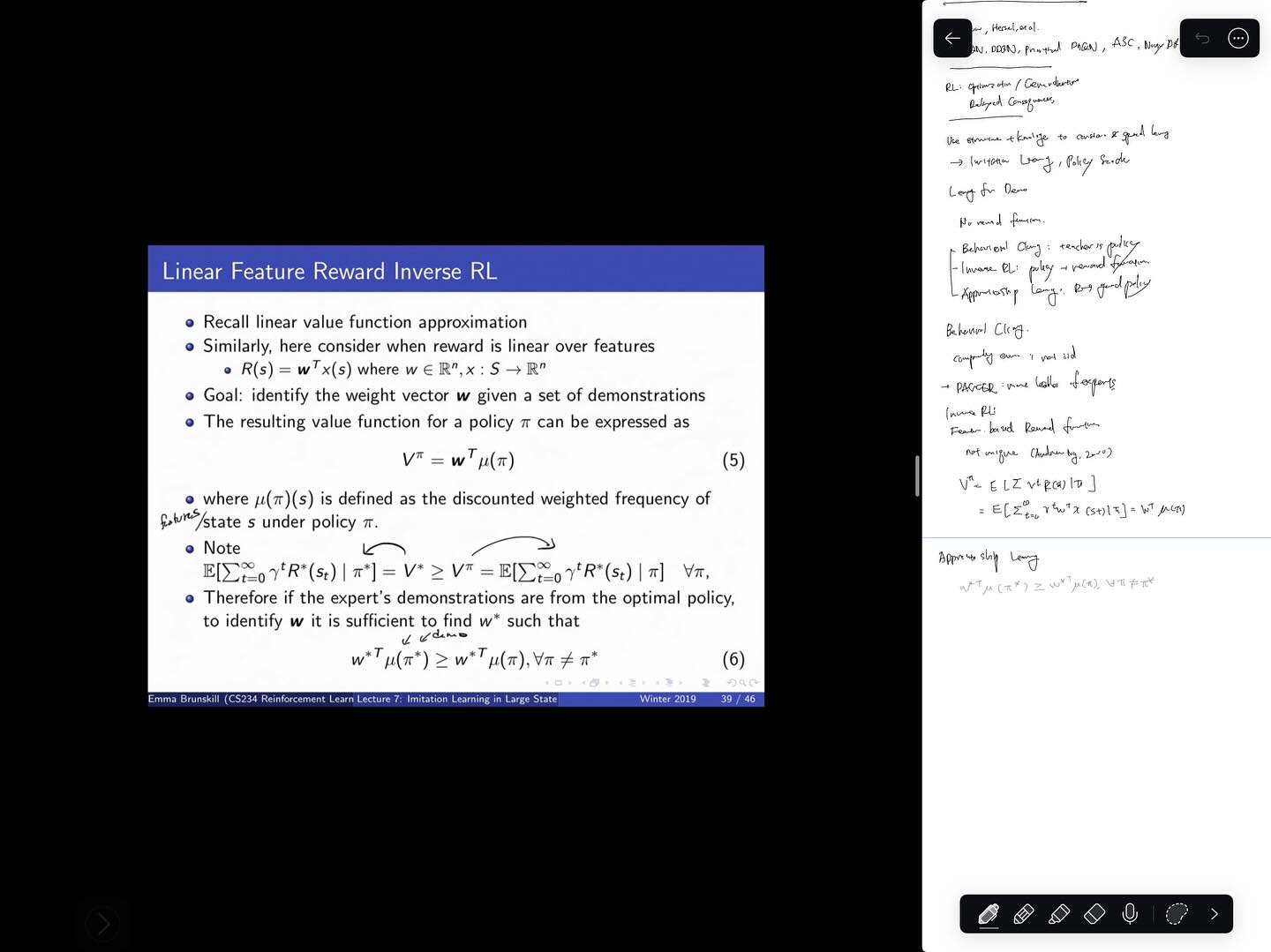
Imitation Learning은 전문가의 시연로부터 어떻게 모방할 수 있는가의 문제를, 전문가의 state, action 샘플로부터 reward function을 추정하거나 이로부터 optimal policy를 학습함으로써 풀고 있습니다.
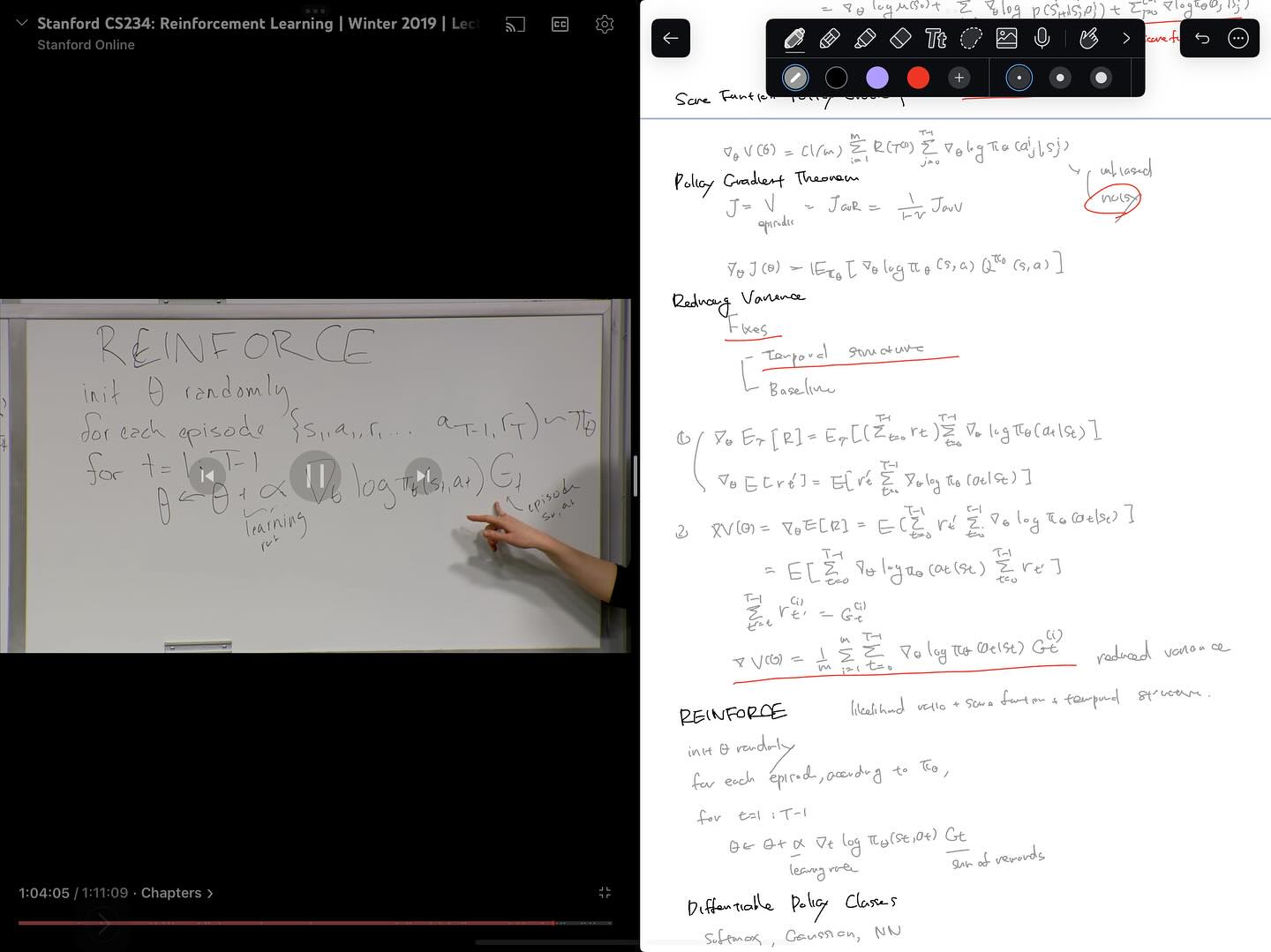
그동안 value function을 학습해서 policy evaluation 및 control을 해왔던 value-based method를 다뤄왔습니다만, 8강에서는 policy 자체를 학습하는 접근을 다루기 시작합니다. policy 자체를 파라미터를 이용해 표현하고, policy의 value를 최대화하는 파라미터를 찾는 최적화 문제로 다룹니다. 최적화 방법에는 여러가지가 있지만, Likelihood Ratio / Score Function Policy Gradient에 temporal structure를 도입함으로써 결국 잘 알려진 REINFORCE 알고리즘을 얻게 되는 과정을 설명합니다.
다음 강의들을 듣는 동시에, Intro to Reinforce Learning의 Chapter 13도 함께 읽어볼 예정입니다.