Exploration을 다루는 CS234 11-13강을 들었습니다.
우선 MDP에 비해 상대적으로 단순한 multi-armed bandits 문제와 regret과 같은 framework의 formulation으로 시작합니다.
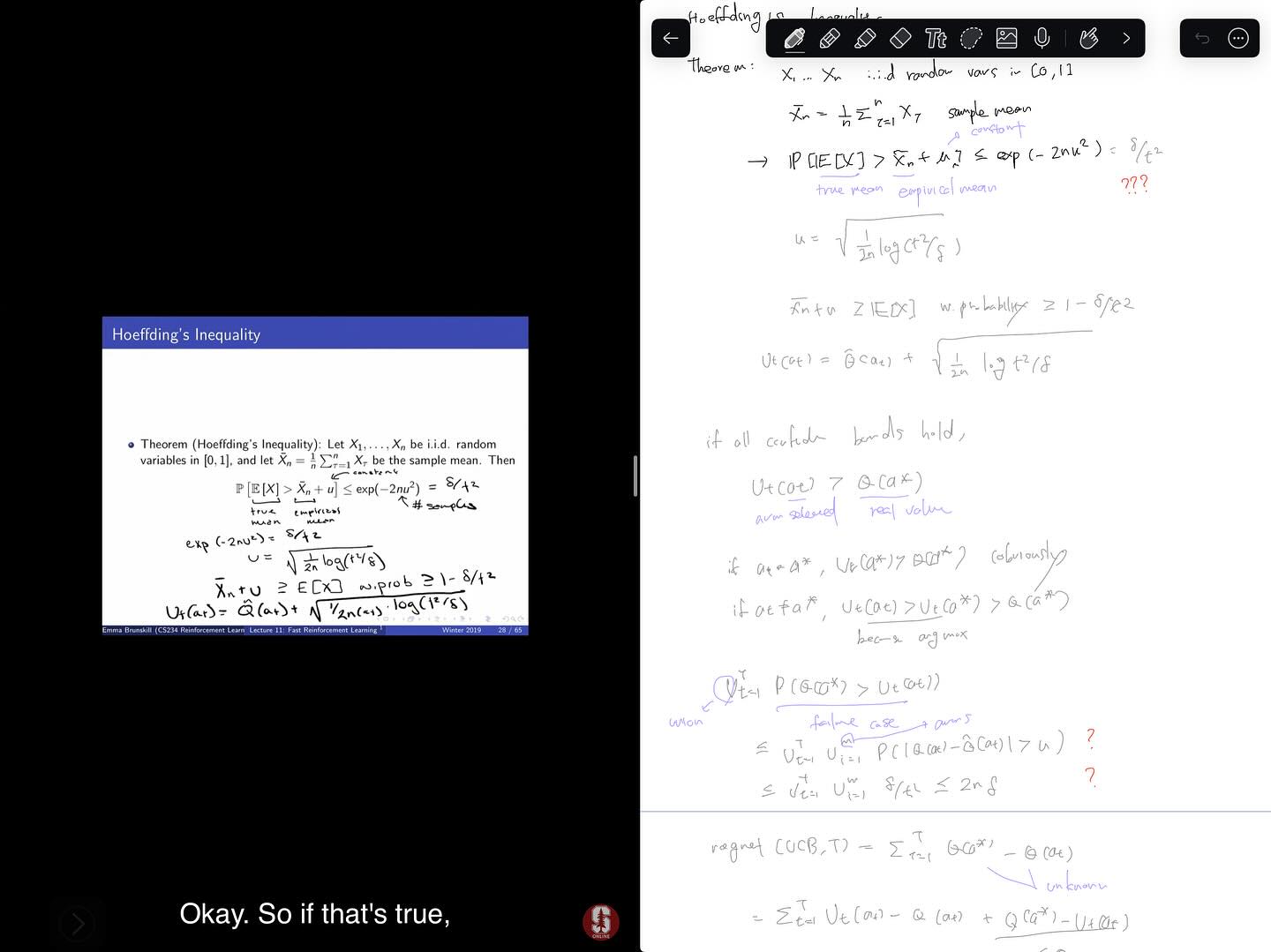
이어서, 불확실한 상황에서 탐색을 통한 정보를 얻는 것의 가치를 높게 보는 Optimism in the face of Uncertainty 원리로부터 UCB1 알고리즘을 설명합니다. UCB 알고리즘들은 여러 경로로 접해왔지만, 이러한 원리 하에서 이해하게 된 것은 처음입니다. 또한, 각 arm들을 확률변수로 보고 Hoeffding’s Inequality를 통해 모르는 정보들을 제거하고 UCB1 알고리즘을 유도하는 과정도 꽤 흥미로웠습니다.
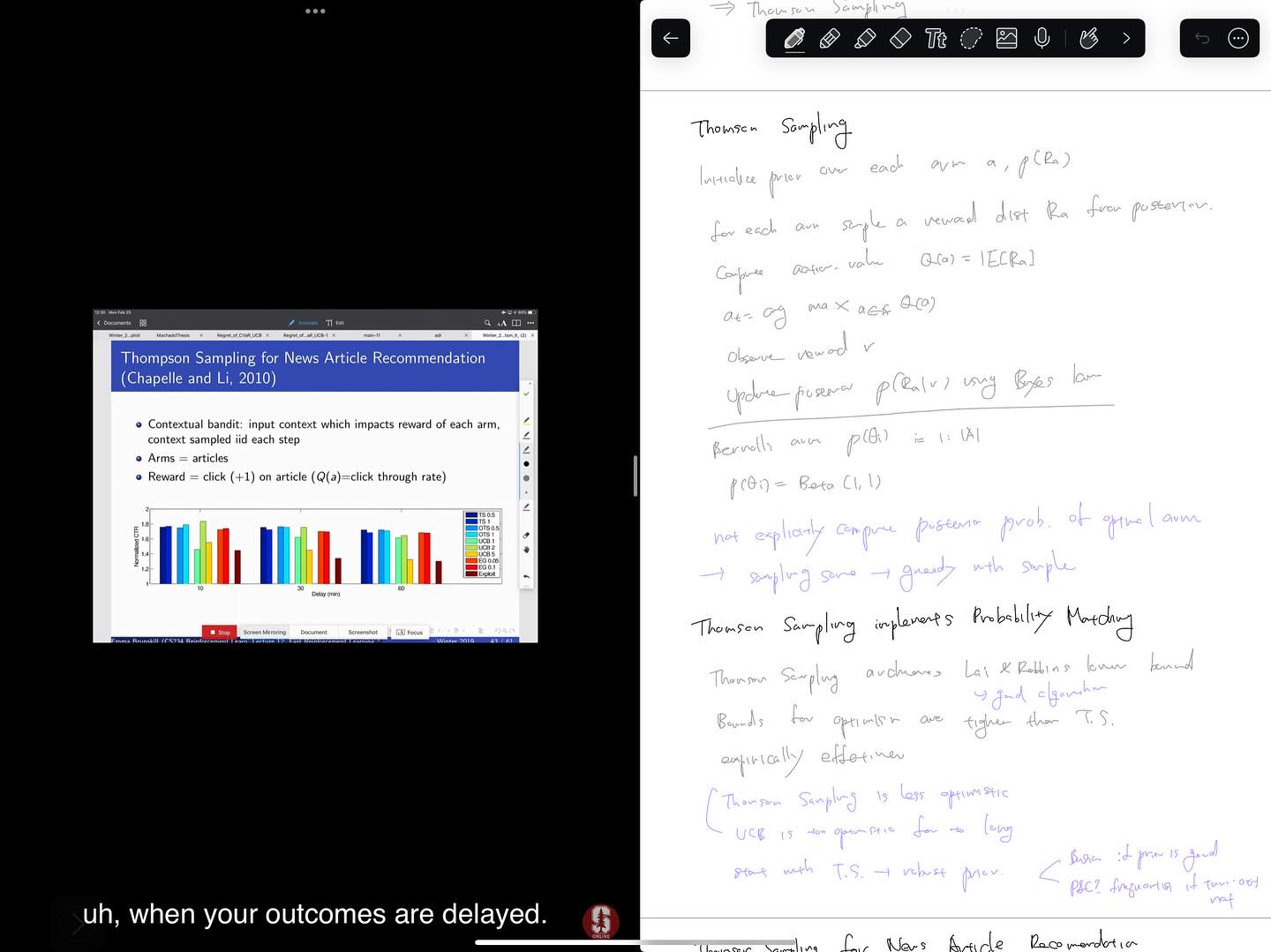
다음으로 reward distribution에 대해 Bayesian inference를 이용하는 Bayesian Bandits을 배우게 됩니다. Bayesian inference는 분석적으로 계산하기 까다로운데 conjugate prior를 통해서 이를 가능하게 하는 것도 처음으로 알게되었습니다. Bayesian bandits 하에서 Probability matching 접근을 하는 대표적인 알고리즘으로 Thomson Sampling이 다루어집니다. Thomson Sampling 알고리즘에서는 posterior로부터 sampling을 하고 이에 기반해 action을 결정하고, 이에 따른 reward를 다시 posterior에 반영하는 단순한 휴리스틱으로 되어있는데, 경험적으로 매우 잘 동작한다고 하네요.
마지막으로 PAC (Probably Approximately Correct) 개념과 이에 해당하는 알고리즘을 배웁니다. Supervised Learning에서와 비슷하게, 일정 이상의 확률로 optimal value로부터 일정 이하의 차이가 보장되는 것을 말합니다. 이러한 알고리즘의 예로 MBIE-EB를 들고 있고 어떤 RL 알고리즘이 PAC을 만족하기 위한 조건들도 다룹니다.
이번에는 강의도 쉽지 않았고 Bayesian Inference에 대해 정확하게 이해하기 위해 별도로 공부를 해야만 했습니다. exploration 방법들을 MDP에 적용하는 내용도 있었지만 이번에는 skip했습니다. 이번에 배운 내용들을 Bandit Algorithms 책과 인터넷에서 다시 한번 복습을 해보고 나머지 강의들을 들을 예정입니다.