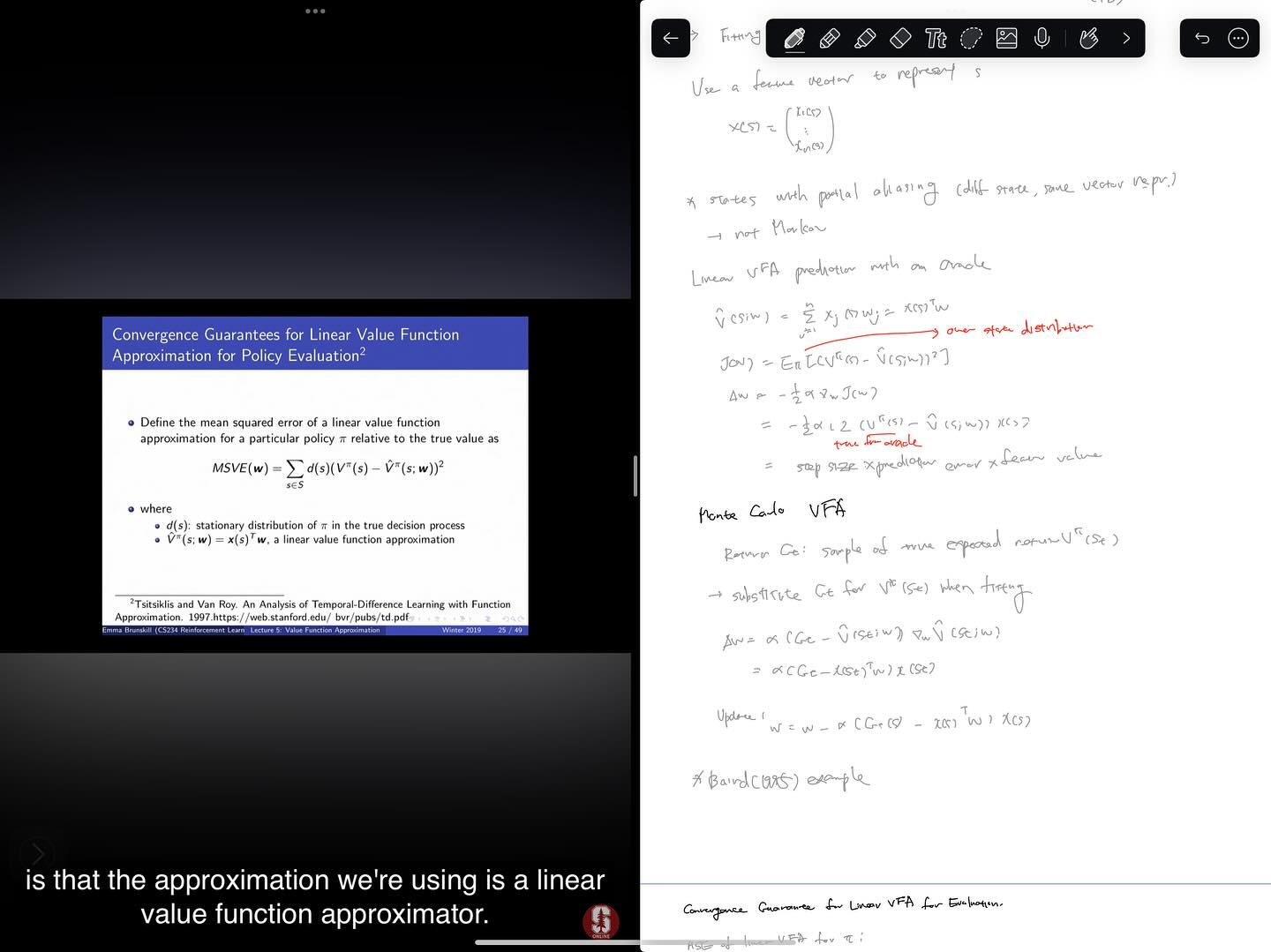
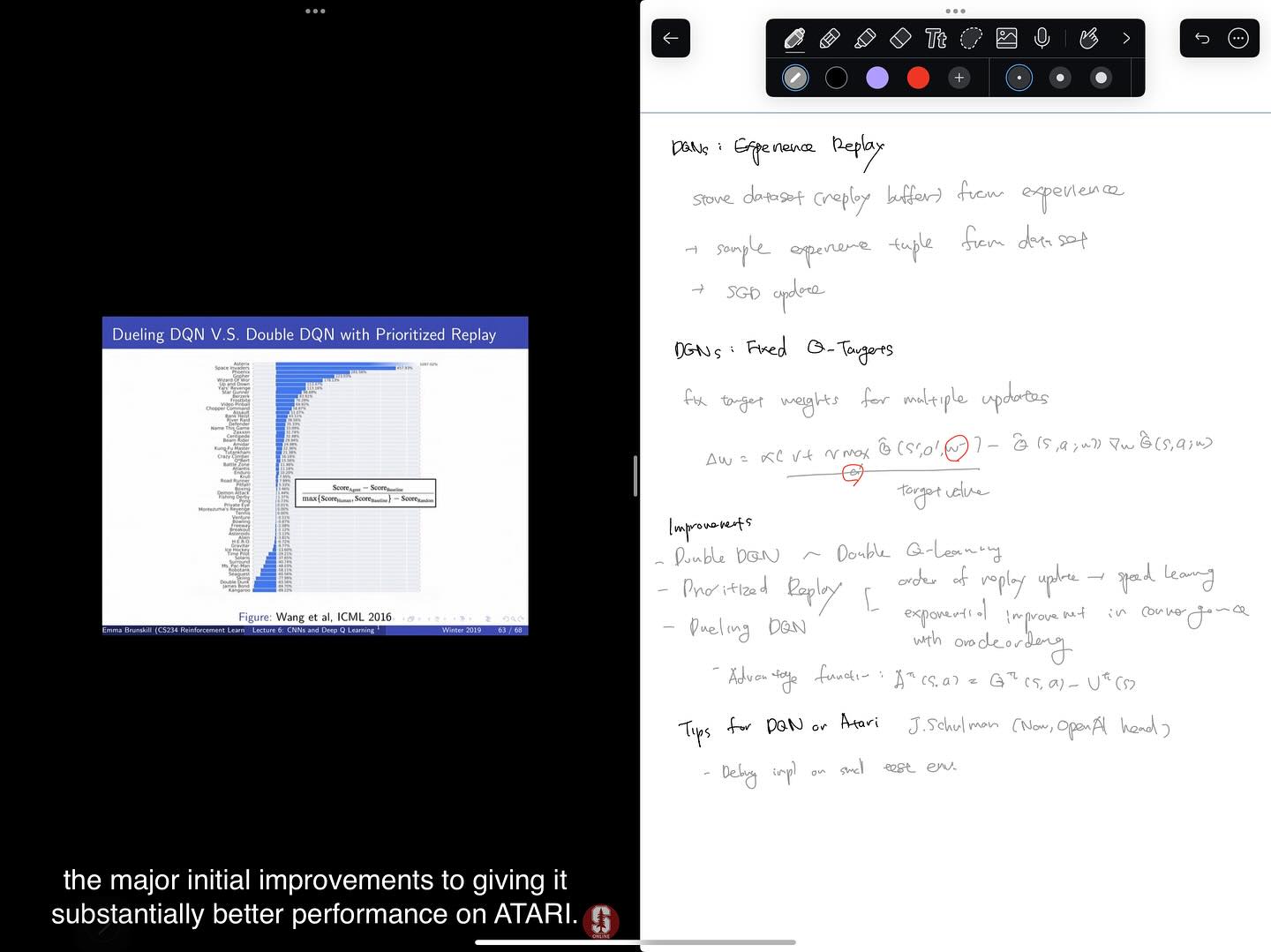
CS234 Reinforcement Learning 강의 6강까지 들었습니다. function approximation으로 넘어갔고, 아타리 게임을 플레이하는 것으로 화제가 되었던 DeepMind의 DQN까지 배웠습니다. function approximation + off-policy에서의 convergence 문제 때문에 관심이 시들하다가 DQN 때문에 다시 많은 관심을 얻게된 것 같네요. 그나저나 TRPO와 PPO의 주저자인 J. Schulman이 OpenAI의 cofounder인 것도 이 강의를 통해 알게 되었네요.