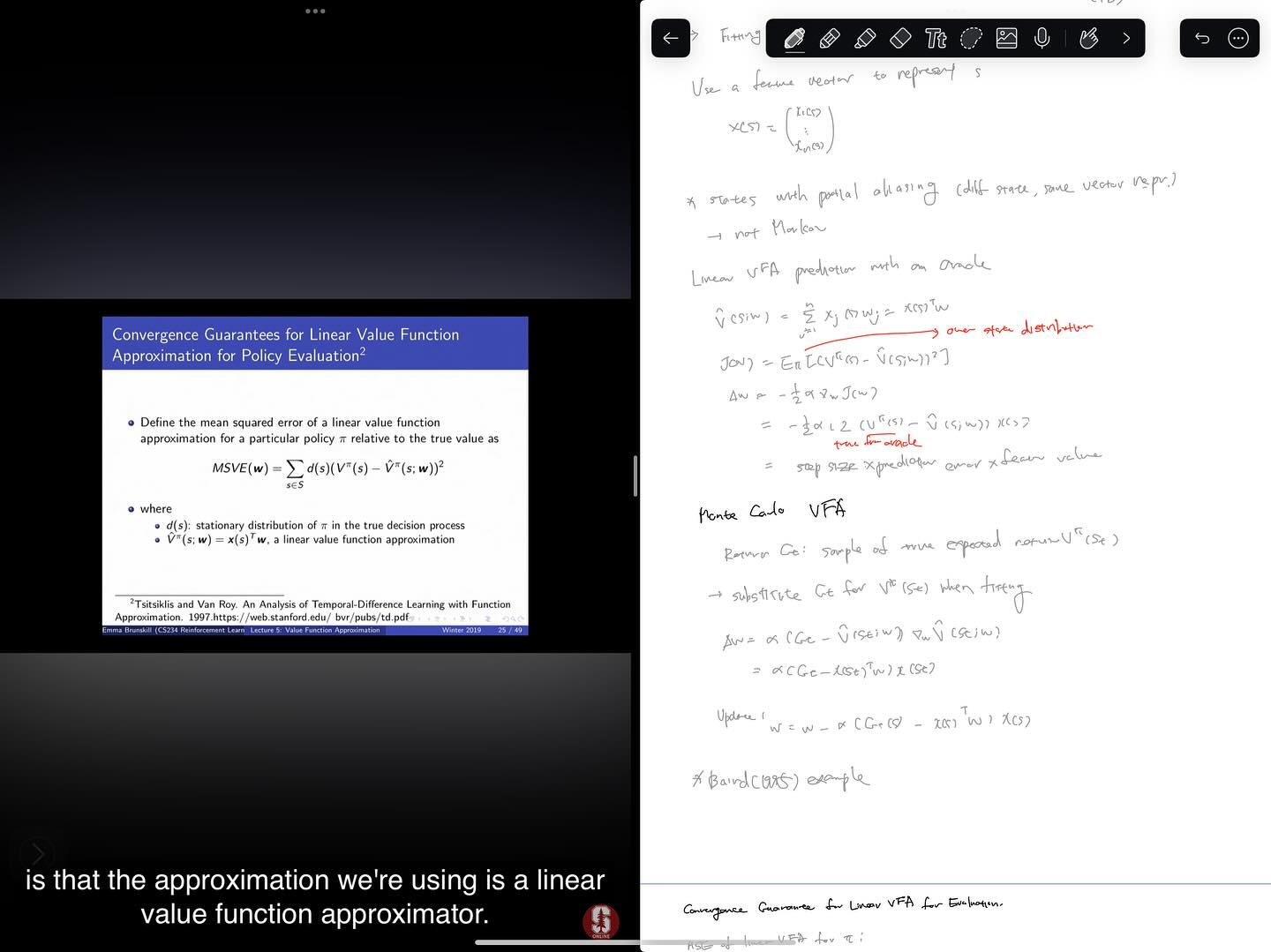
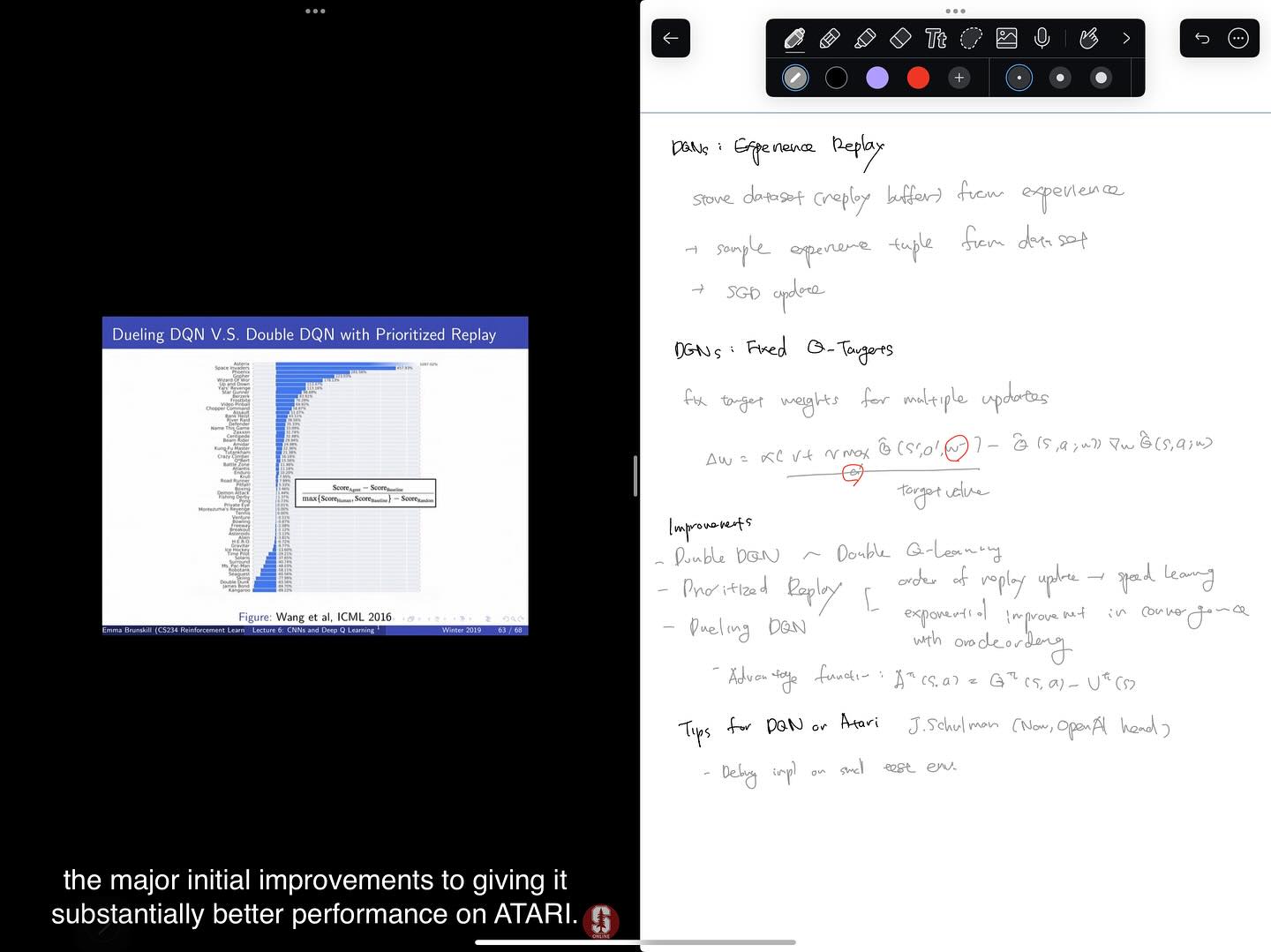
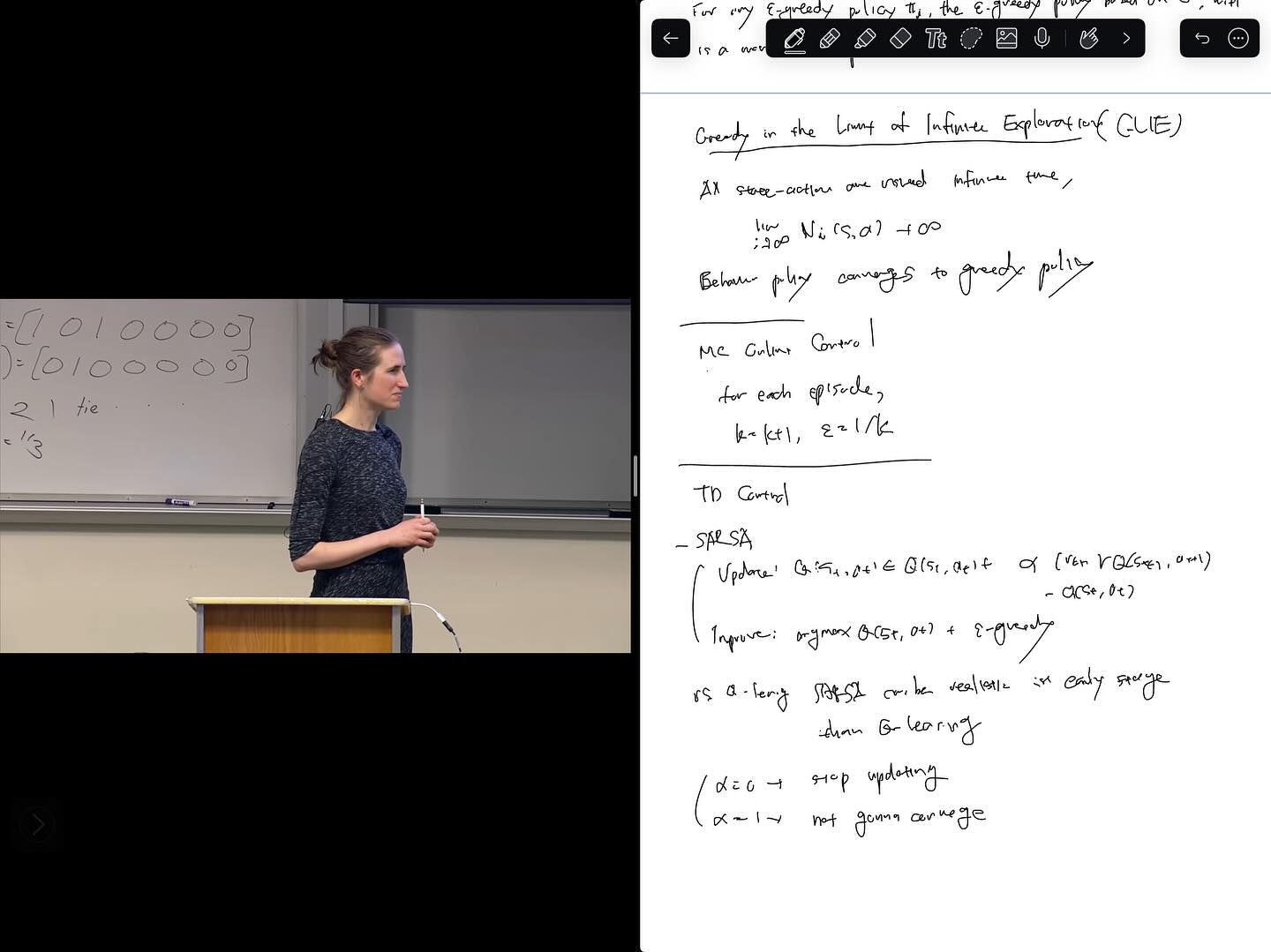
CS234 Reinforcement Learning 강의 6강까지 들었습니다. function approximation으로 넘어갔고, 아타리 게임을 플레이하는 것으로 화제가 되었던 DeepMind의 DQN까지 배웠습니다. function approximation + off-policy에서의 convergence 문제 때문에 관심이 시들하다가 DQN 때문에 다시 많은 관심을 얻게된 것 같네요. 그나저나 TRPO와 PPO의 주저자인 J. Schulman이 OpenAI의 cofounder인 것도 이 강의를 통해 알게 되었네요.
유튜브에 공개되어있는 2019년 겨울의 CS234 Reinforcement Learning 강의 4강까지 들었습니다. 3강을 듣다가 이해하기가 좀 어려워서 RL: An Introduction (Sutton and Barto)의 관련 chapter들을 먼저 읽고나니 강의를 훨씬 편하게 들을 수 있었습니다.
얼마 전 열렸던 DEVIEW 2020의 세션 중 하나인 ‘밑바닥부터 만드는 인공지능 서빙 플랫폼’ 발표를 듣고 그 내용을 요약합니다. 플랫폼 개발의 이유를 명확하게 설명하고 이로부터 이어지는 시스템의 설계 내용이 논리적으로 잘 맞아떨어져서 즐겁게 들을 수 있었던 발표였습니다. 마이크로서비스들의 배포와 서빙을 위한 플랫폼과 머신러닝 배포 및 서빙 플랫폼 사이에 기능적, 기술적으로는 연관관계가 많이 있는 반면에, 둘 사이에 사용자, 환경, 작업 흐름의 차이 때문에 현실적으로는 머신러닝에 국한된 프로덕트가 필요하다는 생각을 가지게 되었습니다.
시작
2019년 초 weight 파일 + 인퍼런스 코드 + flask 서버로 서빙 시작
지금은 각 모듈을 공통화
모델 공통화 동기
모델 수 증가 -> 서빙을 위한 엔지니어링 코스트 증가
지속적인 모델 학습과 배포: A/B 테스트, 로그를 저장하고 이를 통한 학습
사내시스템 연동: 유지보수가 잘 안되는 코드
협업 가능한 환경 구축: 엔지니어가 모델러로부터 받은 인퍼런스 코드를 재작성하는 엔지니어링 코스트. 모델러와 엔지니어의 관심사에 따라 분리.
공통화 요소
게이트웨이
인증, 레이트리미트, 로깅, 트래픽 관리, 비동기 처리
인퍼런스를 위한 공통 라이브러리 (SDK)
모델러 등의 협업 인터페이스 정의
http, grpc 라이브러리 제공
모델 디스커버리, 로깅, 헬스체크 고려 (?)
이종의 환경을 디플로이하기 위한 시스템
이종의 환경을 디플로이하기 위한 단일한 인터페이스
MDS: 공통 모델 패키징
요구사항
ML 프레임워크 – 텐서플로, PyTorch -> 베이스 이미지 제공
REST API -> Decorator/Flask
CPU/GPU 환경 -> GPU 환경을 위한 operator, 배치 처리 기능 추가
종속성/배포 문제로 인해 Docker -> 모든 배포에 Docker 사용
모델 서빙 클래스: 전처리, 인퍼런스, 후처리 코드를 decorator로 지정
모델 서빙 클래스 + 모델 파일로 이루어진 모델 패키지를 생성
mds는 모델 패키지의 서빙 클래스를 flask와 연동하여 서빙
배치 인퍼런스: 여러 리퀘스트를 한꺼번에 처리
멀티 모델 파이프라인
DPLO: 공통 모델 배포
요구사항
CPU/GPU 클러스터 -> 사내 주요 클러스터 오퍼레이터 구현
배포 단계 제어 및 이력 관리 -> 선언적 배포 구성 파일
라우팅 자동화 -> 엔드포인트 자동 등록
모델 패키지를 S3에 업로드하고 DPLO에 배포 요청
DPLO는 패키지를 다운로드 받아서 이미지를 빌드하고 Docker Registry에 업로드
Juchang Lee, Hyungyu Shin, Chang Gyoo Park, Seongyun Ko, Jaeyun Noh, Yongjae Chuh, Wolfgang Stephan, and Wook-Shin Han. 2016. Hybrid Garbage Collection for Multi-Version Concurrency Control in SAP HANA. In Proceedings of the 2016 International Conference on Management of Data (SIGMOD ’16). Association for Computing Machinery, New York, NY, USA, 1307–1318. DOI:https://doi.org/10.1145/2882903.2903734 (pdf)
요약
인메모리 데이터베이스 중 하나인 SAP HANA의 가비지 컬렉션에 대해 설명하고 있는 페이퍼.
MVCC를 구현하고 있는 데이터베이스에서 OLAP 워크로드 등으로 인해 버전을 유지하기 위한 메모리가 증가한다거나 버전들을 처리하기 위한 코스트가 증가하는 것을 방지하기 위해서 가능한 한 사용되지 않는 버전들을 적게 유지하는 효율적인 가비지 컬렉션 메커니즘은 매우 중요하다. 기본적으로 가비지 컬렉션의 대상이 되는 버전들은 현재 실행중인 트랜잭션으로부터 접근이 불가능한 – 미래에도 접근할 필요가 없는 버전들이라고 볼 수 있다. 이를 구현하기 위한 일반적인 접근은 현재 실행중인 트랜잭션이 접근하는 가장 오래된 스냅샷 타임스탬프 (minimum global snapshot timestamp)을 추적하고 이보다 이 전에 생성된 버전들을 삭제하는 것이다.
이 페이퍼에서는 이를 개선하기 위한 구간 가비지 컬렉션 (interval garbage collection), 그룹 가비지 컬렉션 (group gabage collection), 테이블 가비지 컬렉션 (table garbage collection), 그리고 이들을 조합한 하이브리드 가비지 컬렉션 (hybrid garbage collection)을 제안하고 있다.
SAP HANA의 버전 관리
레코드를 변경하는 INSERT/UPDATE/DELETE 오퍼레이션들은 버전 스페이스에 버전을 추가하는데, 버전 스페이스는 레코드 식별자 (RID)를 기준으로 하는 해시테이블로 구성되어있다. 버전 체인은 최근의 버전부터 저장하는 방식 (latest-first)을 채택하고 있다. 인플레이스 업데이트 (in-place update)를 채택한 다른 데이터베이스와는 달리 테이블 스페이스에는 가장 오래된 버전 (oldest version)이 저장되고, 가비지 컬렉션에 의해 테이블 스페이스의 버전이 더이상 액세스되지 않을 때 새로운 버전으로 업데이트된다.
각 버전은 그 버전을 생성한 트랜잭션에 해당하는 TransContext를 가리키고 있고, 그룹 커밋에 의해 동일한 커밋 식별자 (commit ID)를 가진 트랜잭션은 동일한 GroupCommitContext를 가리키게 된다.
전역 그룹 가비지 컬렉터 (Global Group Garbage Collector)
최소 스냅샷 타임스탬프를 효율적으로 얻기 위해서 레퍼런스 전역 STS 트래커 (global snapshot timestamp tracker)를 유지한다. 이는 스냅샷 타임스탬프의 정렬된 리스트로 각각의 타임스탬프는 레퍼런스 카운팅으로 관리된다. 트랜잭션이 시작될 때 레퍼런스 카운트가 증가되고, 종료될 때는 레퍼런스 카운트가 감소되며 0에 도달하면 스냅샷 타임스탬프는 리스트로부터 삭제된다. 최소 스냅샷 타임스탬프를 얻기 위해서는 단순히 전역 STS 트래커 리스트의 첫번째 항목을 액세스하면 된다.
그룹 커밋 단위로 가비지 컬렉션을 수행하기 위해서 GroupCommitContext들이 커밋 ID 순으로 정렬된 리스트를 유지한다. 전역 그룹 가비지 컬렉터는 이 리스트를 순차적으로 방문하면서 최소 스냅샷 타임스탬프와 같거나 더 작은 커밋 ID를 가진 그룹커밋에 해당하는 버전들을 가비지 컬렉션한다.
구간 가비지 컬렉터 (Interval Garbage Collector)
전역 그룹 가비지 컬렉터는 스냅샷 타임스탬프의 최소값 이전만 가비지 컬렉션만 하기 때문에, 최소 값 이상의 타임스탬프를 가진 스냅샷들에 대해서는 한계가 있다. 한편, 최소값 이상의 타임스탬프를 가진 스냅샷이라고 하더라도 버전 체인 내의 모든 버전을 필요로 하는 것은 아니다. 특정 타임스탬프 상에서 생성된 스냅샷은 그 타임스탬프 이후의 버전 하나만을 필요로 하기 때문에, 이 구간에 속하지 않는 버전들은 가비지 컬렉션 대상으로 볼 수 있다.
구간 가비지 컬렉터는 간단히 말해, 실행중인 트랜잭션의 스냅샷 타임스탬프들과 각각의 버전 체인을 비교해서 액세스할 가능성이 없는 버전들을 가비지 컬렉션하는 방식이다. 이 때문에, 매우 정확하지만 비용이 많이 드는 가비지 컬렉션이라고 할 수 있다. 이 페이퍼에서는 이를 위한 모델을 정식화하고 이를 구현하기 위한 머지 기반의 알고리즘을 제시하고 있다. GroupCommitContext 리스트로부터 버전 체인들을 얻는 것으로 설명하고 있고, RID 테이블로부터 얻는 대체 구현도 제시하고 있다.
테이블 GC (Table GC)
SAP HANA의 경우 Stmt-SI라고 불리는 구문 (statement)별로 스냅샷을 가지는 모델을 디폴트로 채택하고 있다. 이 때문에 각각의 스냅샷이 액세스하는 테이블을, 트랜잭션 완료 시점이 아니라, 구문을 해석한 시점에 미리 알 수 있다. 테이블 GC는 이를 통해, 특정 테이블만 액세스하는 스냅샷의 부정적인 효과를 데이터베이스 전체가 아니라 테이블로 제한하는 방식이다.
테이블 GC의 구현은, 오랫동안 살아남은 스냅샷이 액세스하는 테이블을 확인해서, 스냅샷 타임스탬프 객체를 전역 STS 트래커로부터 테이블별 STS 트래커로 이동한 후, 테이블별 STS 트래커로부터 테이블별 최소 스냅샷 타임스탬프를 결정하고, 이를 이용해 각 버전의 가비지 컬렉션에 활용한다.
내부 트랜잭션의 경우 API를 통해 트랜잭션이 액세스하는 테이블을 지정할 수 있기 때문에, 실제로는 Stmt-SI가 아닌 Trans-SI에서도 테이블 GC가 많이 활용된다고 한다.
하이브리드GC (HybridGC)
전역 그룹 가비지 컬렉터, 테이블 가비지 컬렉터, 구간 가비지 컬렉터는 서로 다른 영역에 대해 가비지 컬렉션을 수행하고 있기 때문에, 세가지의 가비지 컬렉터를 모두 채용하는 것이 가비지 컬렉션의 효과성이나 데이터베이스의 성능에 긍정적인 영향이 있음을 보이고 있다.
내가 배운 것 & 생각한 것
데이터베이스 사용자로서 오래 걸리는 (long-lived) 트랜잭션으로 인한 MVCC 데이터베이스의 성능 저하 등의 문제에 대해서는 어렴풋한 개념을 가지고 있었지만, 데이터베이스 상의 가비지 컬렉션 메커니즘에 대해서 자세한 내용을 접해본 것은 이 페이퍼를 읽고 관련된 강의를 들었던 작년 겨울이 처음이다.
효율적인 가비지 컬렉션을 위해서 스냅샷 및 그룹 커밋들의 정렬된 리스트를 활용하고 있다.
구간 가비지 컬렉터에 대해서 수학적인 모델과 알고리즘만 제시하고 있기 때문에 직관적으로 이해하는 것은 조금 어려웠다. 간단한 개념도만 있었다면 매우 이해하기 쉬웠을 것이다. 한편, 실질적인 접근성 (reachability)을 기준으로 모든 버전을 체크하는 것은 Java와 같은 언어 런타임의 가비지 컬렉션과 거의 차이가 없다는 생각이 들었다. 단, 과거의 버전에 대한 액세스가 새로 생겨날 가능성은 없으므로, 언어 런타임의 가비지 컬렉션보다는 동시성에 관한 난이도는 높지 않다고 생각했다.
구간 가비지 컬렉터에 의해 버전 체인의 중간에 있는 버전들이 가비지 컬렉션 될 경우, 만약 델타 버전을 채택하고 있다면 삭제된 구간의 델타 버전들을 통합할 필요성이 있을텐데, 여기서는 그러한 언급이 없는 것으로 보아, 델타가 아닌 각 버전별 값을 저장하는 것으로 보인다.
언어 런타임에서와 마찬가지로 워크로드에 따라서 각각의 가비지 컬렉터에 어느 정도의 CPU 리소스와 동시성을 투자해서 수행할지는 미묘한 튜닝 또는 셀프 튜닝의 문제가 될 것 같다.
인메모리 데이터베이스에서 특정 워크로드에 의해서 가비지들이 갑자기 많아진다면 실용적으로 사용하는 것에 굉장히 크리티컬한 문제가 될 것 같으므로, 특히 인메모리 데이터베이스에 있어서, 신뢰할만한 가비지 컬렉션 메커니즘은 굉장히 중요한 것 같다. 한편, 버전 스페이스 오버플로우가 발생할 경우 오래된 버전을 디스크로 기록하고 일부 트랜잭션을 중지하는 등의 SAP HANA 기능에 대한 언급이 있기는 하다.
Thomas Neumann, Tobias Mühlbauer, and Alfons Kemper. 2015. Fast Serializable Multi-Version Concurrency Control for Main-Memory Database Systems. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data (SIGMOD ’15). Association for Computing Machinery, New York, NY, USA, 677–689. DOI:https://doi.org/10.1145/2723372.2749436 (pdf)
많은 DBMS들이 MVCC를 구현하고 있지만, 대부분의 경우, 직렬성 (Serializability)을 보장하기 보다는 이보다 더 약한 격리 수준인 스냅샷 격리 (Snapshot Isolation; SI) 만을 보장하고 있다. 일반적으로 스냅샷 격리를 직렬적으로 만들기 위해서는 높은 비용이 필요한 것으로 알려져있는데, 이 페이퍼에서는 적은 비용으로 직렬성을 보장하는 MVCC 구현을 제안하고 있다.
이 구현의 기본적인 접근은 메인 테이블에는 최신 버전을 유지하고 in-place update를 하되, 새로운 버전으로부터 오래된 버전 순서대로 (newest-to-oldest) 연결된 버전 벡터를 통해 이전 버전에 대한 액세스를 제공한다.
흥미로운 것은 아직 커밋되지 않은 트랜잭션에 의해 추가되는 버전이다. 위의 그림에서 Ty는 아직 커밋되지 않은 트랜잭션의 ID로 커밋된 시간과 구분하기 위해서 263 이상의 매우 큰 값으로 할당된다. Ty 트랜잭션에 의해 메인 테이블에서는 ‘7’이라는 값이 in-place update되고, 이 값은 Ty 트랜잭션에게만 보이는 값이 된다. 한편, 버전 벡터의 Ty에 해당하는 항목에는 Ty와 Ty 트랜잭션이 일어나기 전의 값이 저장된다. 따라서, T5 이후에 시작된 (Ty 이외의) 트랜잭션에서는 Ty 트랜잭션이 생성한 버전으로부터 ‘8’이라는 값을 얻게된다.
커밋되지 않은 데이터를 가진, 즉 트랜잭션 ID를 가진 버전이 존재하는 레코드에 대해 쓰기 오퍼레이션을 하려는 트랜잭션은 바로 중지되고 롤백된다.
Serializability Validation
직렬성을 보장하기 위해서 트랜잭션에서 일어난 읽기 오퍼레이션들이 다른 트랙잭션에 의해 영향을 받지 않았음을 보장하기 위한 검증 단계 (validation phase)를 필요로 한다.
기존의 방식은 주어진 트랜잭션의 모든 읽기 오퍼레이션을 기록하고, 트랜잭션이 끝나기 전에 다시 한번 읽기 오퍼레이션을 모두 수행함으로써 다른 트랜잭션으로부터의 영향이 없었음을 검증하는데, 이는 스캔이 많은 워크로드에서 굉장히 높은 비용을 요구하게 된다.
이 시스템에서는 Precision Locking이라는 오래된 기법을 이용하는데, 기본적으로 읽기 오퍼레이션이 아니라 읽기 오퍼레이션의 조건 (predicate)들을 기록하고, 검증단계에서는 해당 트랜잭션의 라이프타임 동안 발생한 트랜잭션들의 쓰기 오퍼레이션들이 읽기 오퍼레이션들의 조건과 겹치는 지를 확인하는 방식이다.
검증할 트랜잭션의 라이프타임 동안 발생한 트랜잭션들을 효율적으로 찾기 위해서 최근의 트랜잭션 리스트를 유지하고, 이 트랜잭션에 함께 저장된 undo 레코드를 통해서 쓰기 오퍼레이션들을 확인할 수 있다.
Efficient Scanning
스캔을 할 때 레코드별로 버전 벡터가 존재하는지 여부를 체크하는 것을 피하기 위해, 일정한 범위의 레코드들마다 버전 벡터가 존재하는 레코드의 범위를 저장하고 (VersionedPositions), 이를 통해 버전 벡터가 존재하지 않는 범위에서는 더 빠르게 스캔할 수 있도록 도와주는 메커니즘을 가지고 있다. 불필요한 버전들은 계속 가비지 컬렉션에 의해 제거되므로, 소수의 레코드들만이 버전을 가지고 있는 것을 가정하고 있다.
Evaluation
VersionPositions를 통해서 약 5배 가량의 스캔 throughput 개선이 이루어졌다.
스냅샷 격리 (SI)에 대비해 직렬성을 보장하는 레코드 레벨 조건 로깅이나 애튜리뷰트 레벨 조건 로깅은 약 5-7%의 비용만을 요구했다.
내가 배운 것 & 생각한 것
낙관적인 동시성 제어를 사용하는 MVCC 구현, OLTP/OLAP 둘다에 최적화, LLVM을 이용한 코드 생성 등의 기능들이 상용화되는 인메모리 데이터베이스 구현에서 많이 보이고 있다.
Precision locking을 이용한 낙관적인 트랜잭션의 검증은 듣고나면 당연한 것 같지만, Hyper의 독특한 방식이라고 생각한다. 기존의 데이터베이스에서 반드시 이런 접근을 할 필요는 없었다고 생각하는데, 포인트 쿼리와 업데이트들 만으로 구성된 OLTP 트랜잭션이라면 읽기 집합 (read set)을 이용한 검증이 그리 비효율적이지는 않다고 생각된다. 대량의 스캔을 포함한 OLAP 트랜잭션에 대해서는 2번의 읽기를 하는 것만으로도 비용이 굉장히 높아지므로, 이것을 최근의 트랜잭션 리스트를 유지하는 비용 및 쓰기 집합 (write set)의 크기에 따른 성능 저하와 트레이드 오프한 것으로 볼 수 있는 것 같다.
우리가 흔히 사용하는 데이터베이스에서는 스냅샷 격리를 사용하는 것이 보편적이고 그 이상은 비용효율적이지 않다는 선입견을 가지고 있었는데, 직렬성을 보장하면서도 충분히 좋은 성능을 보여주는 이 페이퍼를 본 후에 그러한 선입견을 깰 수 있었다.
RedisRaft는 Redis Labs에서 개발하고 있는, Raft를 이용해 replication을 구현한 Redis module이다. 약 2018년 초에 PoC 프로젝트로 시작되었고, 2019년 중반부터 본격적으로 개발하기 시작했다고 한다. 실제로 RedisRaft의 GitHub repository를 확인해보아도 Yossi Gottlieb라는 개발자가 약 1년 전부터 commit을 하기 시작한 것을 알 수 있다. 현재는 개발 중이고 2021년에 GA로 내놓을 예정이라고 한다.
실제로 분석을 통해 21개의 버그를 발견했고 다양한 성격의 문제들이 있었지만, RedisRaft가 가져다 사용한 Raft 구현에도 여러 버그가 있었고 치명적인 문제로도 연결되었던 것 같다. Paxos나 Raft 알고리즘은 대략적인 얼개를 구현하는 것은 어렵지 않을지는 몰라도 여러가지 실패 모드들을 제대로 구현하는 것은 굉장히 어렵기로 잘 알려져있다. 참고로, RedisRaft가 사용하고 있는 Raft 구현은 C로 쓰여진 https://github.com/willemt/raft. 이러한 이슈들을 보면 일단 데이터베이스에서도 그렇지만, 분산시스템에서는 더더욱 사려깊게 설계된 테스트가 굉장히 중요하다는 것을 다시 한 번 확인할 수 있었다. 그리고, 정확한 분산시스템을 쓰는 것이 얼마나 어려운 것인지, 그리고 시간이 드는 것인지도 다시금 떠올릴 수 있었다.
한편, Antirez도 이 리포트를 언급하며 Redis를 state machine으로 보고 Raft를 외부에 구현하는 것에 대한 아이디어와 설계에 대해 RedisRaft의 주저자인 Yossi Gottlib과 얘기했었다고 언급했다. 아이디어 자체야 새로운 것은 아니겠지만, 미니멀리스트인 Antirez로서는 충분히 예상되는 디자인. 분산시스템 분야 사람들은 Antriz가 취하는 여러가지 ‘실용적인’ 절충들에 대해서 탐탁치 않아하는 것이 사실이고, Redis cluster 설계에 대한 평가도 그리 좋지 않았다. Jensen의 Kyle Kingsbury도 이에 답글을 달아 이에 대해서 우리가 설득하려고 하지 않았냐고 그러한 논의를 상기시킨다. Antirez는 만약 그랬으면 Redis는 망했을거라고. 거의 Antirez 혼자서 Redis의 대부분의 기능들을 개발하는 상황 상 만약 그가 Raft 구현의 정확성에 시간을 쏟았다면 아마도 다른 부분의 진척은 굉장히 느려졌을거라는 상상은 충분히 할 수 있다. 분산시스템 개발은 그만큼 어렵다. 이렇게 서로 다른 의견을 가진 사람들이지만 어떤 형태로든 협력해서 또다른 좋은 프로덕트가 나오게 된 것은 좋은 일이라 생각한다.
Remember 2013, when a half-dozen of us were desperately trying to convince you that this was a good idea? ;-) https://t.co/P1NFV37ZOJ
일반적인 믿음과는 달리 동시성 제어 프로토콜 보다 버전 스토리지 방식이 인메모리 MVCC 데이터베이스의 scalability에 있어서 가장 중요한 부분이었다.
Delta storage 방식이 메모리 할당 방식과 상관없이 높은 성능을 보여주었다. 특히 튜플의 일부만이 수정될 때 효율적이고, 반면 테이블 스캔에 있어서는 낮은 성능을 보여주었다.
워크로드에 알맞는 동시성 제어 프로토콜을 사용함으로써 성능을 개선할 수 있으나, 전반적으로 여러 워크로드에 대해서 MVTO가 좋은 성능을 보여주었다.
Transaction-level GC가 가장 좋은 성능을 보여주었다.
Logical pointer 방식이 높은 성능을 보여주었다.
내가 배운 것 & 생각한 것
데이터베이스 마다 MVCC를 구현하는 방식 자체가 여러가지 디자인 결정에 따라 달라질 수 있고, 그에 따라 성능도 상당히 달라질 수 있느 점을 알았다.
MVCC에 대한 4가지의 디자인 결정과 각각마다 가능한 옵션에 대해서 비교적 상세히 이해할 수 있게 되었다.
각각의 디자인 결정이 완전히 독립적인 것도 아니거니와, 캐시 레벨의 성능 최적화를 해야하는 인메모리 데이터베이스 특성상, 한번 결정한 디자인 선택을 구현 후 바꾸는 것은 매우 어려운 결정이 될 것이다. 자신의 데이터베이스를 구현한다면 그 데이터베이스가 앞으로 처리해야할 워크로드에 대해서 이해하고, 이에 적합한 디자인 결정하는 것이 매우 중요한 일인 것 같다.
이 페이퍼는 OLTP DBMS의 다양한 동시성 제어 방식들이 굉장히 많은 수의 코어를 가진 환경에서 어떻게 scale하는지 시뮬레이터를 통해서 실험하고, 그리고 bottleneck은 무엇인지 분석하고 있다.
Concurrency Control Schemes
Two-Phase Locking (2PL)
어떤 요소를 액세스하기 위해서는 먼저 lock을 얻어야하는 pessimistic 방식이다. 2PL은 필요한 lock들을 얻는 growing phase와 lock들을 릴리스하는 shirinking phase로 이루어진다.
2PL은 deadlock을 어떻게 처리하느냐에 따라서 다음의 3가지 변형들이 존재한다.
2PL with Deadlock Detection (DL_DETECT)
deadlock detector가 트랜잭션 사이의 wait-for 그래프 상의 사이클을 탐지해서 만약 데드락이 발견될 경우 어떤 트랜잭션을 중지시키는 방식.
2PL with Non-waiting Deadlock Prevention (NO_WAIT)
데드락이 발생한 후에 이를 탐지하는 것이 아니라, 데드락이 발생하리라 의심되면 lock이 실패하도록 하고 트랜잭션이 중지되는 방식.
2PL with Waiting Deadlock Prevention (WAIT_DIE)
어떤 트랜잭션이 먼저 시작했지만 lock을 얻지 못했을 경우, lock을 가진 트랜잭션을 기다릴 수 있는 방식. timestamp ordering을 위해서 각 트랜잭션은 타임스탬프를 얻어야 한다.
Timestamp Ordering (T/O)
트랜잭션의 serialization 순서를 미리 생성하고 이에 따라 실행하는 방식이다. 각각의 트랜잭션은 단조증가하는 유일한 타임스탬프를 배정받고, DBMS는 이를 이용해 충돌하는 오퍼레이션들을 적절한 순서대로 처리한다.
T/O의 변형들은 충돌 체크를 위한 granularity와 충돌 체크를 어느 시점에 수행하는 지에 따라 다음의 4가지로 나뉜다.
Basic T/O (TIMESTAMP)
DBMS는 트랜잭션의 타임스탬프와 트랜잭션이 액세스하려는 tuple을 마지막으로 액세스한 타임스탬프를 비교해서, 마지막으로 액세스하기 전의 트랜잭션은 거부하는 방식이다. tuple이 lock에 의해 보호되지 않으므로 repeatable reads를 위해 읽기 쿼리는 tuple의 로컬 복제본을 만들어야 한다. 트랜잭션이 중지되면, 새로운 타임스탬프를 부여받고 재시작된다.
Multi-version Concurrency Control (MVCC)
쓰기 오퍼레이션은 트랜잭션의 타임스탬프가 붙어있는 새로운 버전의 tuple을 생성한다. 읽기 오퍼레이션은 버전들의 리스트에서 어느 버전을 읽을 지 결정함으로써 모든 오퍼레이션의 serializable ordering을 유지한다.
MVCC의 이점 중 하나는 늦게 도착한 트랜잭션이 거부되지 않고 기존의 버전을 이용해 실행될 수 있다는 점이다.
Optimistic Concurrency Control (OCC)
트랜잭션의 모든 쓰기 오퍼레이션은 독립적인 공간에서 이루어지고 commit하는 시점에 트랜잭션의 읽기 오퍼레이션들이 다른 트랜잭션의 쓰기 오퍼레이션들과 겹치는지를 검사한다. 겹치는 것이 없다면 쓰기 오퍼레이션의 결과가 데이터베이스로 쓰여지고, 그렇지 않다면, 트랜잭션은 중지되고 재시작된다.
OCC의 이점은 실제로 데이터베이스에 쓰기 오퍼레이션이 이루어지는 구간이 작기 때문에 contention이 줄어든다는 것이다.
Silo나 Microsoft의 Hekaton과 같은 구현이 있다.
T/O with Partition-level Lock (H-STORE)
데이터베이스는 파티션들로 나뉘고 각각의 파티션은 lock에 의해 보호되고 각 파티션 별 실행 엔진 – 단일 쓰레드에 의해서만 액세스될 수 있다. 트랜잭션은 트랜잭션이 액세스하려는 모든 파티션에 대한 lock을 얻어야 한다.
트랜잭션이 도착하면, 각 파티션의 lock을 얻기 위한 큐에 추가된다. 각 파티션의 실행 엔진은 큐로부터 트랜잭션을 꺼내와서 그 트랜잭션의 타임스탬프가 큐 내에서 가장 오래된 것일 때 lock을 얻을 수 있도록 한다.
Smallbase와 H-Store와 같은 구현이 있다.
Design Choices and Optimizations
각각의 접근을 변경하지 않는 선에서 scalability를 높이기 위해 적용한 최적화들을 설명하고 있다.
General Optimizations
Memory Allocation
malloc bottleneck을 피하기 위해 tcmalloc/jemalloc와 유사하게 쓰레드별 메모리 풀을 유지하는 malloc 구현을 개발. 워크로드에 따라서 풀의 크기를 조정하는 것이 차이라고.
Lock Table
컨텐션을 줄이기 위해서 중앙 집중적인 lock table 대신 튜플별 lock을 사용.
Mutexes
deadlock detector나 timestamp allocator에 사용되는 뮤텍스를 줄이거나 없앰.
Scalable Two-Phase Locking (2PL)
Deadlock Detection
deadlock detection 알고리즘의 데이터구조를 각 코어별로 파티셔닝해서 lock-free하게 만듬.
Lock Thrashing
컨텐션이 높은 상황에서 lock을 기다리는 시간으로 인해 성능이 저하되는 현상이 보임.
Waiting vs. Aborting
트랜잭션의 중지 타임아웃을 조정함으로써 중지 비율과 lock thrashing 사이의 트레이드 오프를 조정할 수 있다.
이 페이퍼의 실험에서는 100us로 고정했으나, 애플리케이션의 워크로드 특성에 따라 조정되어야 할 것이라고 얘기하고 있다.
Scalable Timestamp Ordering (T/O)
Timestamp Allocation
atomic addition을 사용하더라도 1000 코어 상황에서는 cache coherence traffic에 의해 타임스탬프 할당이 bottleneck이 됨.
Silo에서 제안된 것처럼 batched atomic addition을 사용하는 방법, CPU clock을 사용하는 방법, 빌트인 하드웨어 카운터를 사용하는 방법을 제안하고 있다.
batched atomic addition을 사용할 경우 컨텐션이 높은 상황에서 conflict로 인해 재시작된 트랜잭션이 timestamp ordering에 의해 계속 재시작되는 현상이 성능 저하의 요인이 된다.
코어들 사이에 동기화된 clock은 인텔 CPU에서만 제공된다고 한다.
빌트인 하드웨어 카운터는 현재의 CPU들에서는 존재하지 않는다고 한다.
Distributed Validation
OCC의 validation 스텝이 상대적으로 짧지만 scalability에 문제가 되기 때문에, 튜플별 validation을 사용함으로써 해결했다고 한다.
Local Partitions
H-STORE 프로토콜에서 다른 파티션의 튜플을 액세스하기 위해 각 파티션별 쓰레드 사이에 IPC를 하는 대신 shared memory를 이용해서 오버헤드를 줄임.
DBMS Bottlenecks
실험을 통해 다음과 같은 bottleneck들이 식별되었다.
lock thrashing
preemptive aborts
deadlocks
timestamp allocation
memory-to-memroy copying
워크로드에 따라서 어떤 알고리즘이 더 나은 성능을 보이기 때문에, 상황에 따라서 2개 이상의 알고리즘을 조합 – 컨텐션이 낮을 때는 DL_DETECT, 높을 때는 NO_WAIT – 하거나, 둘 이상의 알고리즘을 채용 – MySQL의 DL_DETECT + MVCC – 할 수 있다고 얘기하고 있다.
또한 타임 스탬프 할당이나, 메모리 카피 등의 문제를 해결하기 위해서 여러가지 형태의 하드웨어 지원이 필요하다고 얘기하고 있다.
Multi-core vs. Multi-node Systems
여러 노드의 시스템에서는 분산 트랜잭션이라는 새로운 성능 bottleneck이 생겨나기 때문에 대규모의 OLTP 시스템이 아니라면 오히려 커다란 DRAM을 가진 단일 many-core 시스템이 더 나을지도 모른다고 얘기하고 있다.
Future Works
여러 동시성 제어 알고리즘 들의 bottleneck은 알고리즘에 내재한 문제들이므로 소프트웨어만으로 해결하기 어렵고 하드웨어와 협동해서 해결해야한다고 얘기하고 있다.
동시성 제어 알고리즘은 DBMS의 여러 컴포넌트 중의 하나일 뿐으로 다른 컴포넌트들 – logging, index 구현 등에 대해서도 비슷한 분석이 이루어지면 유익할 것이라고 얘기하고 있다.
이 페이퍼의 실험은 여러 코어를 가진 하나의 CPU에 대한 실험이므로 여러 소켓을 가진 시스템에 대한 실험이 필요하다고 얘기하고 있다.
내가 배운 것들 & 생각한 것들
내게는 동시성 제어 알고리즘을 크게 2PL과 T/O로 분류하고 그 안에 MVCC등이 들어갈 수 있다는 것이 새로운 지식의 구조화에 해당하는 것이어서 큰 도움이 되었다.
실험을 수행하기 전에 수행한 최적화로부터 이러한 알고리즘을 구현할 때 맞닥뜨리는 가장 기본적인 bottleneck에 대해서 알 수 있었다.
1000 코어는 아직은 데이터센터에서 흔히 볼 수 있는 시스템은 아니라서 조금 비현실적이라는 생각이 들지만, AWS 등에서도 96 vcpu 정도의 compute 리소스를 할당할 수 있는 점을 생각하면, 200-500 코어 시스템에 대해서 고민하는 것도 그리 먼 미래는 아닌 것처럼 보인다. 특히, 굉장히 긴 수명주기는 가진 소프트웨어라고 할 수 있는 데이터베이스의 경우에는 10년 정도의 스케일을 바라보고 디자인 결정들을 해야하는 부분도 있으리라 생각한다. 다만, 그러한 시스템을 필요로 하는 워크로드가 존재하는지만 문제일 것이다.
컨텐션이 높아지면 어떤 알고리즘이라고 해도 절대적인 성능 자체가 order of magnitude로 떨어지므로, 사실상 워크로드에 알맞는 파티셔닝 외에는 해결책이 없는 것으로 보인다.
일반적인 굉장히 많은 사용자 서비스를 제공하는 웹 서비스들의 워크로드에서 실험에서와 같이 컨텐션이 높은 워크로드 (theta=0.8)는 흔치 않다고 생각한다.
컨텐션이 심하지 않고, 500 코어 이하의 구간을 보자면 NO_WAIT, MVCC 등이 최고는 아니라고 하더라도 적절히 높은 수준의 성능을 보여주고 있는데, NO_WAIT는 abort rate가 너무 높기 때문에, 결국은 MVCC가 그나마 괜찮은 선택지가 아닌가 싶고, 추측이지만, 실제 인메모리 데이터베이스 시스템들도 그래서 MVCC를 많이 채용하고 있는 것이 아닌가 싶다.
이 페이퍼에서는 인메모리 데이터베이스 시스템에서 Logging, Locking, Latching, Buffer management 등의 기능을 하나씩 제거했을 때 어떠한 성능 변화가 일어나는지를 보여주고 그 결과로부터 미래의 OLTP 데이터베이스에 대해 시사하는 바가 무엇인지에 대해서 논하고 있다.
하드웨어의 변화 그리고 수많은 데이터 중심 애플리케이션들로부터 나타난 다양한 요구 때문에, 표준적인 OLTP 데이터베이스 시스템에서 당연시 되어왔던 logging, concurrency (latching, locking), B-tree, buffer management와 같은 기능들의 일부분만을 가진 데이터베이스들 – Logless/Single-threaded/Transaction-less 데이터베이스들이 나타나고 있다.
Shore라는 표준적인 OLTP 데이터베이스 아키텍처를 가진 데이터베이스 시스템에 인메모리 워크로드를 실행하는 실험 셋업을 갖추고, logging, latching, locking, buffer management 등의 기능을 하나씩 제거하면서 instruction의 수가 어떻게 변화하는지를 측정했다.
실험 결과를 통해 logging, latching, locking, buffer management와 같은 기능들이 전체 대비 상당히 높은 CPU 비용을 소비하는 것을 알 수 있었다.
이러한 결과로부터 미래의 OLTP 데이터베이스 엔진에 대해 다음과 같은 방향성을 제시하고 있다.
동시성 제어 (Concurrency Control)
dynamic locking은 disk-based OLTP 데이터베이스일 때 좋은 선택이었지만, 메모리 기반 워크로드의 경우에는 다시 따져볼 필요가 있고, optimistic concurrency control 방식이 더욱 나은 선택지가 아닌가 하는 의견을 제시하고 있다.
멀티코어 지원 (Multi-core Support)
많은 수의 코어를 가진 컴퓨터가 늘어나고 있고, 동시성이 높은 프로그램들이 성숙하고 있기 때문에, latching과 관련해 더 나은 구현과 멀티쓰레딩의 부담에 대해서 탐색해볼 필요가 있다고 얘기하고 있다.
다른 옵션으로는, 각각의 머신은 하나의 코어를 가진 컴퓨터처럼 볼 수 있는 가상화 환경이 갖춰졌음을 언급하고 있는데, 아마도 각각의 데이터베이스 시스템은 싱글쓰레드 시스템으로 동작할 수 있게 된 것을 함축하고 있는 듯 하다.
이러한 두가지의 접근을 보완해서, 하나의 쿼리를 병렬적으로 처리할 수 있는 시도에 대해서도 언급하고 있다.
복제 관리 (Replication Management)
logging을 이용한 active-passive 복제의 경우 여러가지 문제점들을 가지고 있지만 이렇게 밖에 할 수 없었던 이유는 log를 실행하는 것이 복제본에서 트랜잭션을 실행하는 것보다 훨씬 적은 비용이 들었기 때문인데, 인메모리 데이터베이스 시스템에서는 트랜잭션의 비용이 매우 낮으므로, active-active 복제에 대해서 고려할 수 있다고 얘기하고 있다.
이 때, two-phase commit을 이용하는 것은 추가적인 지연이 너무 크기 때문에 timestamp ordering등의 테크닉을 이용해야하리라고 제안하고 있다.
Cache-conscious B-trees
데이터 구조를 최적화하기 보다는 이외의 부분 – 동시성 제어나 복구 – 을 최적화하는 것이 더 중요한 것 같다고 얘기하고 있다.
하지만, 그러한 최적화 후에는 B-tree의 캐시 미스가 새로운 bottleneck일 수 있고, 다른 데이터 구조도 살펴봐야 한다고 얘기하고 있다.
내가 배운 것
2008년 시점에 이미 학계에서도 전통적인 OLTP 데이터베이스로부터 다른 접근들이 나타나고 있었고, 인메모리 데이터베이스라는 커다란 트렌드가 이미 시작하고 있었던 것 같다. 그러한 트렌드를 정확히는 알지 못하지만, 적어도 여러 다른 페이퍼나 제품들의 역사를 보면 2000년대 후반부터 2010년에 중반까지 그러한 트렌드가 이어졌고 그 결과 현재와 같이 수많은 상용 인메모리 데이터베이스 제품들이 나오게 된 것 같다.
전통적인 OLTP 데이터베이스 엔진에서 대부분의 logging, latching, locking, buffer management의 CPU 비용이 80% 이상에 이를 정도로 높은지에 대해서는 전혀 알고 있지 못했다. 기존에는 디스크 액세스가 커다란 bottleneck이었겠지만 적어도 인메모리 데이터베이스 시스템을 만든다면 이러한 기능들에 대해서 세심한 주의를 기울여서 디자인 선택을 해야할 것 같다.
이 페이퍼에서 제시하고 있는 방향성에 대해서, 실제로 이 페이퍼에서 수행할 실험결과로부터 직접적으로 도출되는 방향성이라고 보기는 매우 힘들고, 다만 그 당시 시점의 트렌드나 분위기를 설명하고 있는 것으로 이해했다. 각각의 이슈에 대해서 더욱 엄밀하고 자세히 설명하고 있는 페이퍼들이 많으리라고 생각하므로 심각하게 받아들이지는 않아도 될 것 같다.
이 페이퍼를 읽고 역시 2000년대 후반에 시작된 프로젝트인 레디스가 어떤 동기로 시작하게 되었을까 많이 생각을 해보았다. 이 페이퍼에서 얘기하고 있는 디스크 기반 데이터베이스 시스템과 멀티쓰레드 지원, 트랜잭션 지원 등의 오버헤드를 완전히 제거해버린 시스템이니까. 그리고, 인메모리 데이터베이스 시스템을 만든다면 레디스와 대비해 어떤 기능적인 장점을 가져야 하고 그러인한 성능 오버헤드에 대해 어느 부분을 신경을 써야하는 가에 대해서 고민하는 시발점이 되었다.