How AI Is Changing Our Work
데이블에서는 매달 회사 구성원들이 모두 모인 자리에서 경영진들이 돌아가서 성과와 방향성을 설명하는 Monthly Sharing을 진행합니다. 저는 CTO로서 Engineering 관점에서 특히 중요하다고 생각하는 성과와 계획을 공유하고, 이를 가능하게 한 구성원들을 치하하기도 합니다. 하지만, 무엇보다도 제가 공을 들이는 부분은, 우리가 이미 충분히 고민하거나 실행하고 있는 일들이 아닌, 우리가 앞으로 고민해야하는 일에 대한 저의 생각을 정리해서 공유하는 Ideas 파트입니다.
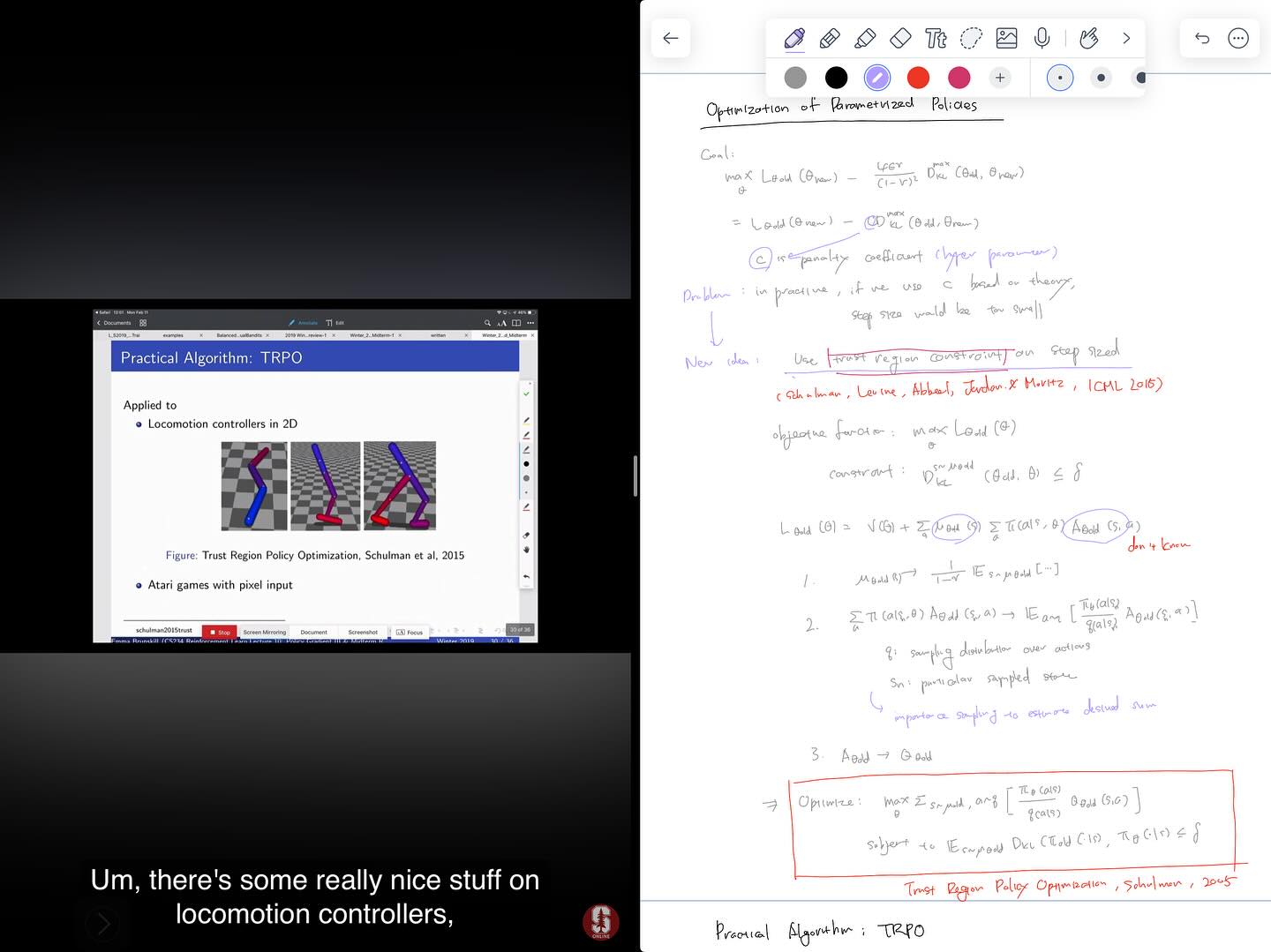
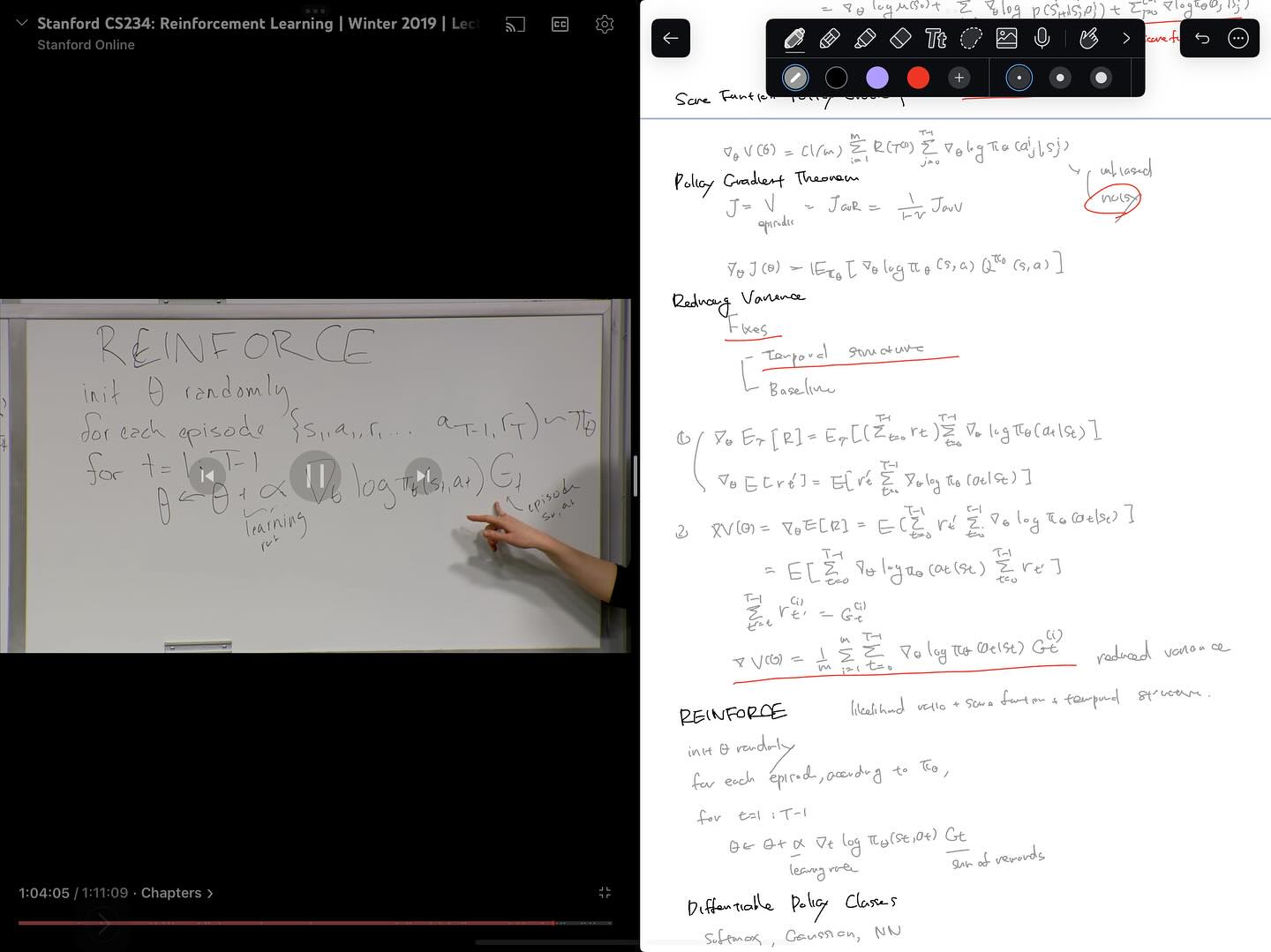
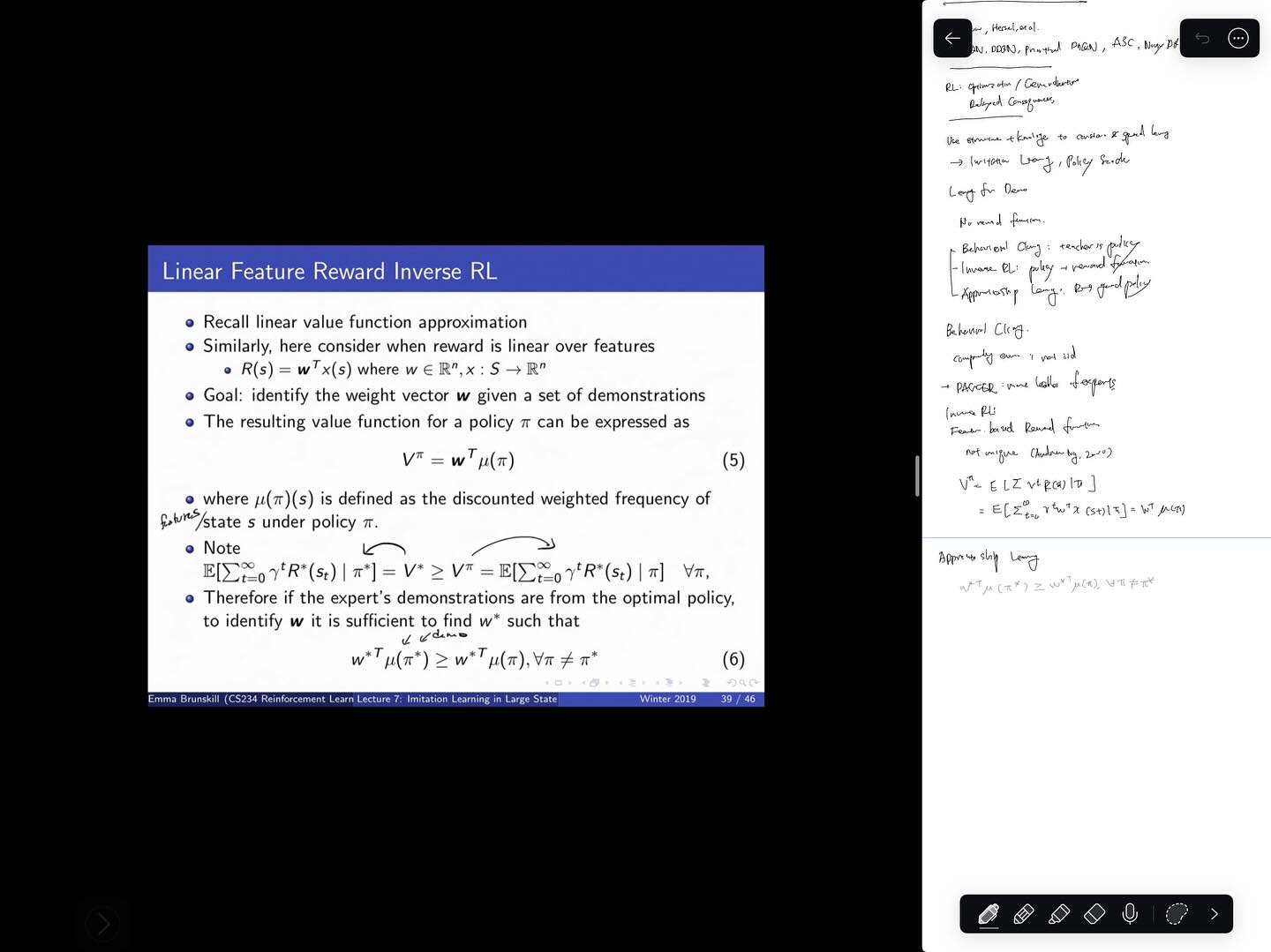
모두가 경험하고 기억하듯, 2025년 하반기는, AI가 소프트웨어 엔지니어의 일하는 방식에 커다란 충격을 던져준 시기였습니다. 저를 포함해 많은 분들은 이러한 변화에 빠르게 적응하고 다음 단계로 올라서기 위해 노력했지만, 동시에 경험많은 시니어 엔지니어들조차도 불안감을 표현하고 있던 시기였습니다. 제가 주로 접하는 Reddit이나 Twitter 등에서도, 충격과 불안함, 허탈함의 표현들도 많았지만, 의외로 이러한 변화의 본질이 무엇이고, 우리들의 역할은 이런 것일거라는 생각들도 많이 논의가 되었고, 저는 어느 정도 일관된 컨센서스가 있다는 생각을 했습니다. 물론, 이러한 생각들은 앞으로 있을 변화의 속도나 전환을 생각하면 모두 무너질 수 있는 것들이지만, 아무리 한치 앞을 볼 수 없는 시기라고 하더라도, 그렇다고 해서 아무것도 하지 않는 것보다는, 우리 안의 지도를 계속 그려나가며, 길을 찾는 노력을 지속하는 것은 중요하다고 생각했습니다.
마침 2026년 1월에 저의 Monthly Sharing 발표 순서가 돌아오게 되었고, 소프트웨어 엔지니어 또는 소위, 지식노동자들이 앞으로 어떻게 변화해야하는가에 대한 얘기를 해보고 싶었습니다. 동료들의 불안함을 덜어주려는 목적도 없지는 않았지만, 그보다는 우리가 변화하지 않으면 안된다는 생각이 더 컸습니다. 요즈음 발표 자료를 만들 때 다들 그러하듯이, 먼저 저의 생각을 텍스트로 정리하고, AI의 도움을 통해 1차적으로 프리젠테이션에 알맞는 간결한 텍스트로 정련한 다음, 역시 AI의 도움을 얻어 디자인을 입히는 식으로 발표 자료를 준비했습니다. 다만, 발표에는 20분 가량의 짧은 시간이 주어지기에, 제 생각을 모두 전달하지 못했을 수도 있다는 생각을 했습니다. 그래서, 이를 조금 더 자세히 설명해보고 싶었고, 지금에서야 글을 쓰게 되었네요.
다시 한번 강조하고 싶은 것은, 제가 이 글에서 다루는 내용들은 저만의 생각이 아니라, 꽤나 많은 사람들이 동의할 수 있는 생각들이고, 훨씬 도전적인 생각들은 의도적으로 제외했습니다. 즉, 이 생각들이, 다가올 미래에 대해 상상의 나래를 펼친 것이 아니라, 이미 다가온 현재를 다루고 있다는 점을 다시 한번 말씀드리고 싶습니다.
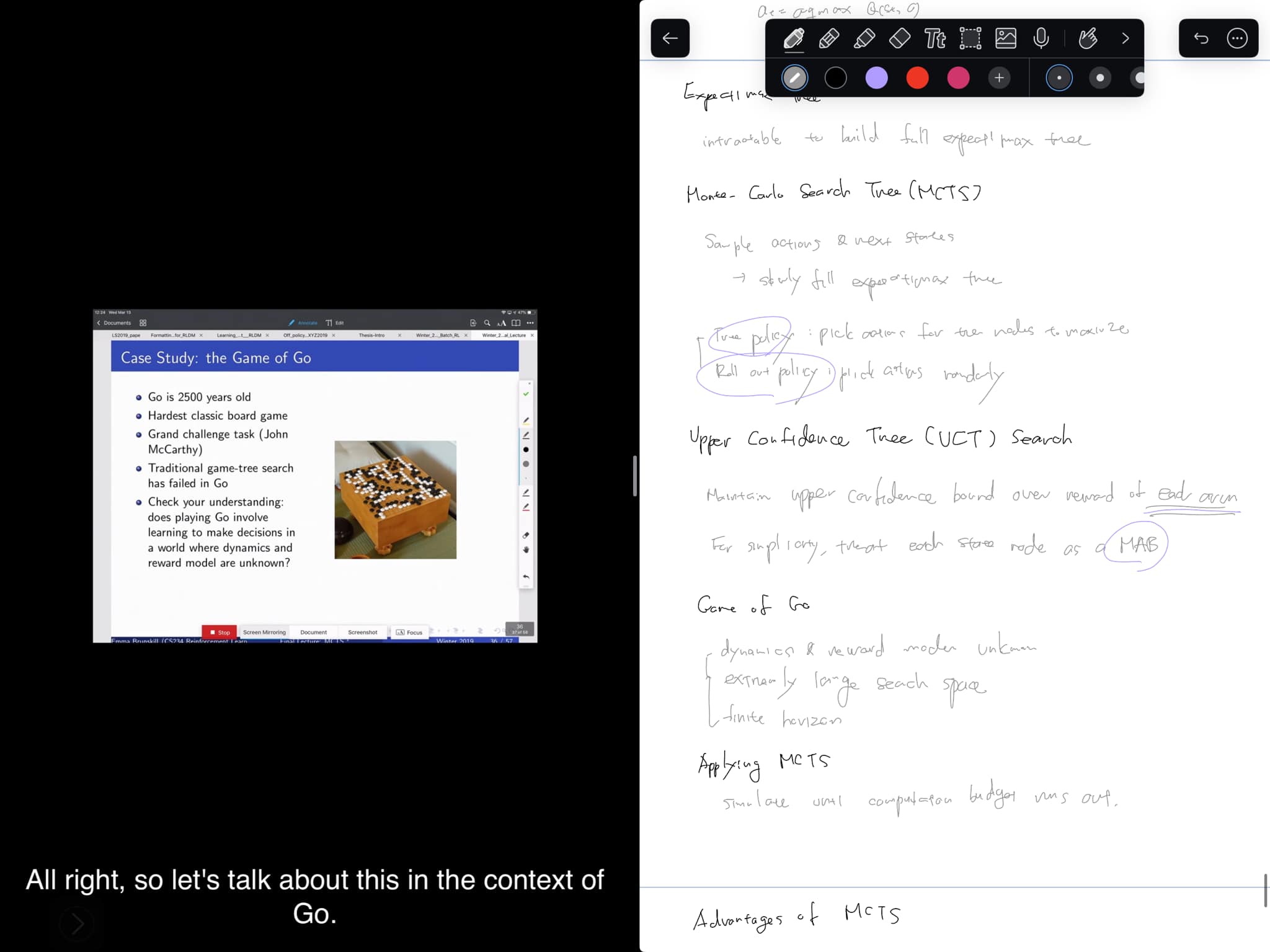
Shift 1: From “How to Build” to “What to Achieve”

소프트웨어 엔지니어로서의 일 중에서, ‘How’의 문제, 즉, 문제를 어떻게 해결하는가의 영역의 많은 영역을 AI가 처리할 수 있게 되었습니다. 물론, ‘How’를 완전히 AI에게 맡길 수 있다고 장담할 수 있는 상황은 아직 아닙니다만, ‘How’의 영역의 커다란 부분을 AI가 다룰 수 있게 되었다는 것은 소프트웨어 엔지니어라면 누구나 동의할 수 있을 것입니다.
인간은 ‘What’과 ‘Why’를 여전히 맡고 있습니다. AI가 ‘What’과 ‘Why’도 할 수 있지 않느냐고 묻는다면, 그러한 흉내를 낼 수 있지만, 결국 현재까지의 세상은 인간이 원하는 것을 이루기 위해 움직여왔고, 적어도 앞으로 10-20년 정도는 그러한 본질이 변하지는 않으리라고 생각합니다. 언젠가 AI가 인간의 선과 욕망을 결정하는 세상이 올 수도 있겠지만, 그러한 세상이 올 때까지 인간과 AI가 경쟁하고 다투는 과정에는 많은 시간이 걸릴 것이라고 생각합니다. 그러한 과도기의 도입부에 해당하는 현 시점에서, 아직은 소프트웨어 엔지니어는 인간으로서, 우리가 원하는 것이 무엇이고, 그래서 어떤 문제를 풀어야하는지를 다루어야만 합니다.
구체적으로, 소프트웨어 엔지니어는, 우리의 의도 – 무엇을 만들고 싶은지 – 를 명확하게 표현하는 일, 그리고 그러한 과정에서 어떠한 제약이 존재하고, 성공의 기준이 무엇인지를 들추어내고 정의하는 일, 실제로 최종적인 결과물이 그러한 기준과 제약, 의도에 들어맞는지를 검증하고 판단하는 일에 집중해야합니다.
한가지 짚고 넘어갈 부분이 있습니다. 여전히 소프트웨어 엔지니어는 ‘How’도 다룰 것입니다. 한편, LLM이 태어나지 않은 세상에서도 그동안 사양서나 테스트 계획을 작성하는 일을 해오지 않은 것도 아닙니다. 커다란 변화는, AI와의 분담을 통해, 소프트웨어 엔지니어가 집중해야하는 영역이 ‘How’에서 ‘What’과 ‘Why’로 크게 기울어진다는 것입니다.
Shift 2: Blurring Boundaries Between Engineering Roles

이러한 변화의 결과로, 엔지니어링 역할들 사이의 경계가 희미해질 수 밖에 없습니다. ‘How’에 대한 주도권을 AI에게 넘긴다는 것은, 소프트웨어 엔지니어가 분화된 역할에서 가지고 있던 ‘How’에 대한 지식과 경험들의 의미와 가치가 줄어든다는 것을 의미합니다.
‘What’과 ‘Why’가 중요해지기에, 일의 시작과 끝, 즉, 어떤 것을 왜 만들어야하고, 그것이 만들어야 했던 이유가 충족되었는지 판단하는 일이 중요해집니다. 현재까지는 이러한 것들을 잘하는 엔지니어도 있지만, ‘How’만 잘하는 엔지니어도 있고, 또 중요했습니다. 앞으로는, 올바른 일을 시작하고, 올바르게 일을 끝맺을 수 있는 end-to-end problem solver들의 가치가 높아질 것입니다.
소프트웨어 엔지니어의 가치를 따질 때, 지금까지는 문제와 관련된 영역에 특정한 전문성을 가지고 있느냐를 빼놓을 수 없었습니다. 앞으로는 그러한 장면은 점점 줄어들 것이라 생각합니다. 이제는 어떤 소프트웨어 엔지니어가 과연 문제 해결을 시작부터 끝까지 풀어낼 수 있는가, 그 과정에서 필요한 여러 행동 요소들 – 도메인 지식과 경험, 커뮤니케이션, 협력 행동, 책임감 – 을 포함하는 Ownership을 가지고 있는가가 훨씬 더 중요한 요소가 될 것입니다.
Shift 3: Declining Cost Differences Between Technologies

‘How’에 대한 주도권을 AI에게 넘기는 것은 우리가 지금까지 가지고 있었던 기술이나 기술 작업에 대한 비용 이해를 완전히 바꿔놓게 됩니다.
지금까지는 어떤 프로그래밍 언어나 프레임워크를 도입할 때, 그것들을 이해하고 실수가 줄어들 때까지 훈련하는 비용을 항상 중요하게 다룰 수 밖에 없었습니다. 물론, 여전히 기술 선택은 비용에 영향을 미칠 것입니다. 하지만, 우리가 지금까지 경험하거나 생각했던 것보다 차이가 크게 줄어들 것입니다.
현재의 변화가, 기술 도입의 결론들까지도 뒤흔들어 놓을 것이라는 결론에 너무나도 쉽게 도달하게 됩니다. 우리가 그동안 경험으로 또는 간접적으로 몸에 익혔던 기술 비용의 감각은 틀린 것이 될 수 있습니다. 때분에, 기술 비용에 대한 판단을 할 때, 지금까지 우리가 알고 있었던 것을 버리거나, 매우 주의해서 다루어야 할 필요가 있습니다. 진정으로 ‘Unlearning’이 중요해지는 이유이기도 합니다.
기술 결정을 수행할 때, 그 기술이 현재 비즈니스나 시스템의 요구에 알맞는가에 더해서 우리 팀이나 조직이 그 기술을 숙련되게 다룰 수 있는가를 그동안 함께 고려해왔지만, 후자의 중요도가 떨어졌기 때문에, 우리는 좀 더 비즈니스나 시스템에 의거한 결정을 할 수 있는 자유가 늘어난다는 점은, 기술의 본질적인 가치를 높이는 좋은 변화라고도 볼 수 있을 것 같습니다.
이러한 기술 결정을 하는 소프트웨어 엔지니어들에게 요구되는 역량에도 영향을 미치게됩니다. 현재까지는 기술의 학습 능력이나 태도, 취향이 무시 못할 중요한 요소였지만, 앞으로는, 기술 결정을 현재 및 미래의 비즈니스나 시스템의 변화를 고려해서, 전략적으로 수행하는 역량이 훨씬 더 중요해지게 됩니다.
So What?

소프트웨어 엔지니어들은 뭘 해야하는건데? 라는 질문으로 시작한 글이기 때문에, 이에 대한 답을 할 시점이 된 것 같습니다. 사실 이미 위에서 그러한 답들은 모두 이루어졌지만, 소프트웨어 엔지니어로서 앞으로 중요하게 다루어야 할 역량들은 다음과 같다고 생각합니다.
- 소프트웨어를 통해 해결해야하는 문제를 명확하고 정확하게 정의하는 스킬이 필요합니다.
- 해결하려는 문제가 정말로 해결되었는지를 매우 효율적이고, 또한 정확하게 검증할 수 있어야 하고, 그러한 체계를 만들 수 있어야 합니다.
- 문제 전체를 혼자서 다룰 수 있는 역량과 태도를 갖추어야 하고, 문제와 관련한 비즈니스 도메인에 대한 이해도가 경쟁력이 될 것입니다.
- 복잡한 요소가 있는 문제를 체계적으로 분석할 수 있어야 하고, 미래의 문제를 예측하고 이에 따라 바람직한 설계를 할 수 있어야 합니다.
이러한 역량들은 원래부터 소프트웨어 엔지니어가 가져야 할 역량들이었지만, 변화의 흐름에서 이러한 역량들의 중요도가 훨씬 높아졌습니다.
문제는 이러한 역량들은 몇번의 연습을 하거나 문서를 읽는다고 해서 얻어지는 것이 아니라는 점입니다. 많은 고민과 다양한 상황에서의 훈련을 통해서만 얻어지는 역량들입니다.
그래서, 당장 오늘부터 다음과 같은 훈련을 의식적으로 시작하시는 것을 제안합니다.
- 자신이나 자신의 팀의 의도나 문제를 명확하게 문서로 표현합니다.
- 어떻게 하면 소프트웨어를 정확하면서도 완전히 자동으로 테스트할 수 있을지 고민하고 시도를 시작합니다.
- 결과물의 품질에 대한 ownership을 적극적으로 가져갑니다.
- 오늘 내가 다루고 있는 기술과 작업, 도구들의 비용에 대해 다시 생각해봅니다.
Closing
AI 기술들의 발전과 이러한 변화들에 대한 인식이 퍼지는 데는 어느 정도 갭이 있습니다. 빠르게 행동하는 분들은 즉각적으로 발전이나 논의들을 수용하지만, 어느 정도 널리 퍼지는 데에는, 제 개인적인 느낌으로는 3-6개월의 시간이 걸리는 것 같습니다. 제가 이 발표를 했던 것이 2026년 1월 9일이었고, 약 3개월 남짓이 지난 현재 시점에서 볼 때, 이 글에서 다룬 생각들은 많이 퍼져있는 편이라고 생각합니다. 그래서 어떤 분들은 너무 반복되어서 지겨운 내용이라고 생각하는 분들도 계실거라고 생각합니다.
그럼에도 불구하고, 저는 이러한 생각들을 반영하는 실질적인 변화들은 아직 보편적이라고 말할 수 있는 단계는 아니라고 생각하고 있습니다. 아마도 생각을 행동으로 옮기는 데에는 시간이 걸리고, 또한 이것들은 조직적인 문제와도 결부되어 있기 때문에, 더 많은 시간이 걸릴 수 있다고 생각합니다.
그래서, 널리 퍼져있거나 이미 지루한 생각일지 몰라도, 생각을 명시적으로 글로 표현하고, 또 한국어로도 다루어보고 싶었습니다.
마지막으로, 많은 경험을 가지고 있고 또 다른 소프트웨어 엔지니어들을 이끌고 도와주는 역할을 하고 계시는 시니어 소프트웨어 엔지니어 분들께는 특별히 당부드리고 싶은 것이 있습니다. 우리들 중 많은 분들은, 수많은 AI 뉴스들을 보고 이것들을 따라가기에 급급합니다만, 단순히 변화에 적응하는 것이 아니라, 변화의 본질이 무엇인지 좀 더 고민해주시고, 그러한 고민의 결과들이 우리의 엔지니어링 프로세스와 조직들에 반영되려면 어떤 변화가 필요한지, 어떤 것을 먼저 시도해봐야 하는지 앞장서서 이끌어주시면 좋겠습니다. 어떤 미래가 올 것인지 걱정하며 따라가는 것에 바쁜 것보다는 우리가 적극적으로 미래를 고민하고 그 미래를 만들어가는 것이, 혹여 실패하더라도, 그 과정은 무척이나 재미있고 보람이 있을 것이라고 확신합니다.