엔지니어링 문제든 매니지먼트 문제든 단편적인 인상에 기초해서 판단내리는 것을 경계하고 판단의 기준을 설정하고 이에 따라 기계적으로 판단을 내리려 노력하는 편이고, 또 그러한 것을 좋아한다. 그럼에도 불구하고 나의 내면 또는 다른 사람으로부터 기원한 강력한 인상이나 직관이 동작할 때, 특히 그것들이 나의 논리나 증거들과 다를 때는, 그것에 일말의 진실이 있을 수도 있지 않을까 자주 의심하게 된다. 이로 인해서 내 생각 내에서도 객관적인 판단이 흐려지는 경우도 가끔씩 있는 것 같다. 현실은 이보다는 복잡하기는 하지만… 단호하게 나의 논리와 증거 기준에 따라서 이야기하는 것이 중요해보인다.
심지어 정중하게 표현되었더라도 다른 사람의 평가에 대해 실제에 비해서 너무 무게를 실을 필요는 없다. 다른 사람의 관점에서 다른 사람의 가치에 의한 평가이기 때문에 나의 가치와는 다를 수 있다. 어떻게 표현되었는가와 관계없이 말 한마디가 가진 정당한 가치로 평가하고 이에 대해 내가 변화가 필요한지 어떤 변화가 필요한지만 정하면 된다. 다른 사람의 한마디 평가, 그에 따라 주어진 보상이나 지위는 일시적이고, 내가 본질적으로 올바른 행동을 하는가 또는 내가 그로 인해 행복한가와는, 길게 보면, 생각보다 그리 관련성이 없다.
Policy Search를 다루는 CS234 Reinforcement Learning 9-10강을 들었습니다.
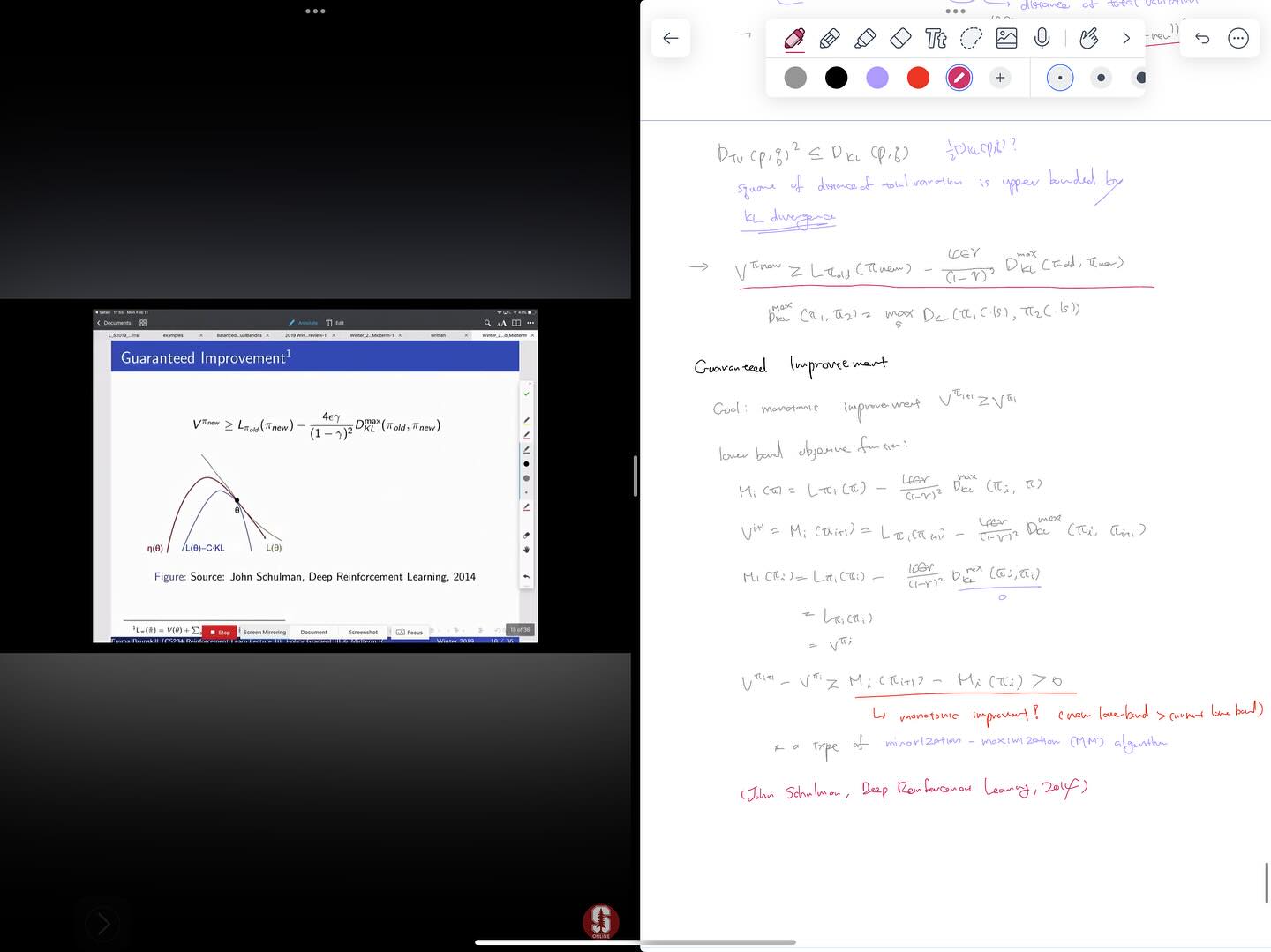
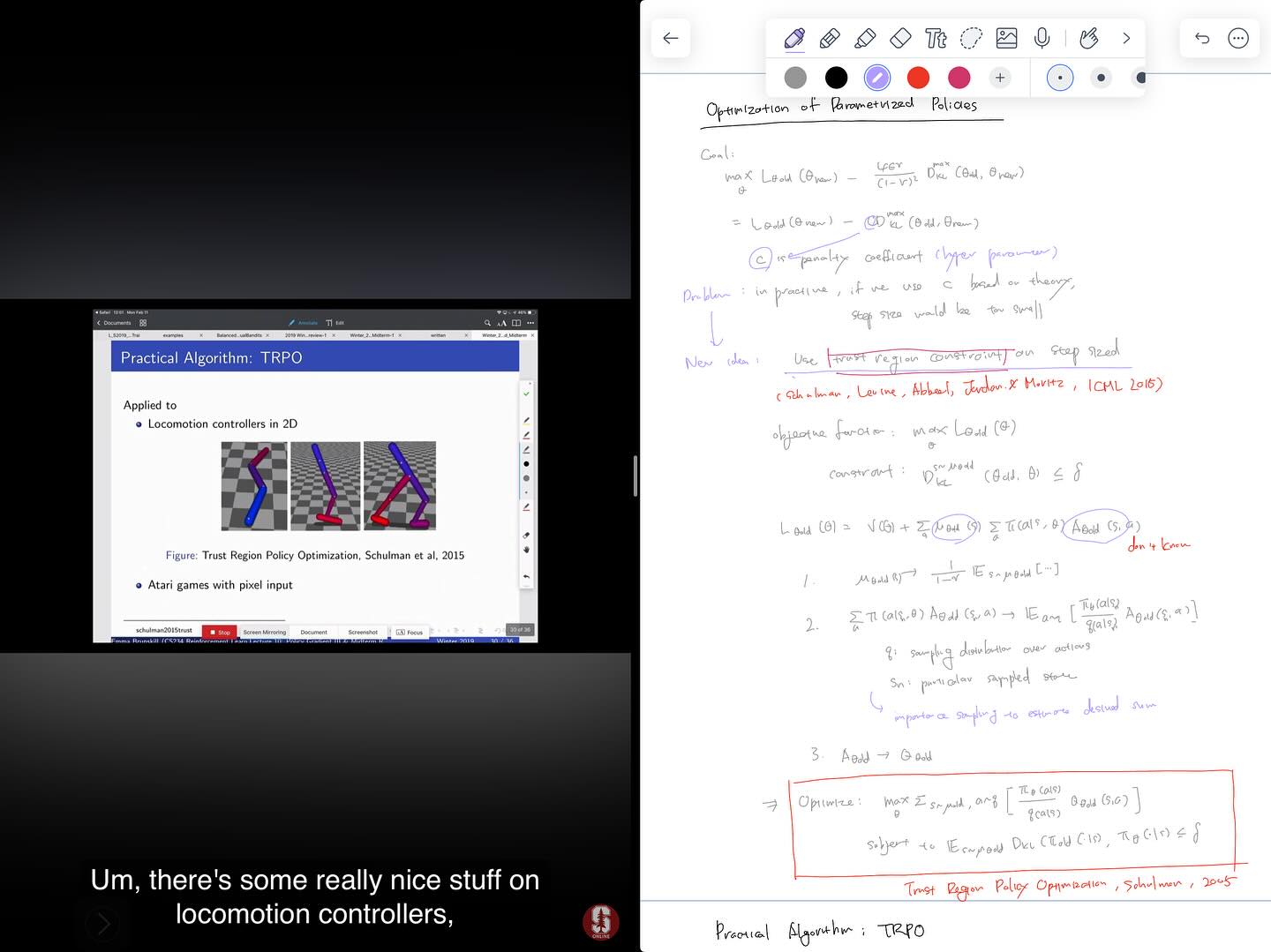
9강은 Sutton Chapter 13에서도 다루고 있는 REINFORCE with baseline에 관한 내용입니다. 10강에서는 이러한 Policy Gradient method에서 monotonic improvement를 보장하기 위해서 step size를 결정하는 문제를 다룹니다. 여기서 매우 유명한 TRPO (Trust Region Policy Optimization) 알고리즘에 이르는 과정을 배우게 됩니다. Policy gradient의 iteration에서 새로운 policy의 value를 알 수는 없지만, lower-bound를 계산할 수 있고, 이러한 lower-bound가 개선되는 것을 보장할 수 있는 objective function과 constraint를 제안합니다. 이를 통해서 policy value를 최대화하면서 안정적인 학습이 이루어질 수 있도록 step size를 결정하는 알고리즘이 TRPO 알고리즘입니다.
계산이 어려운 문제를 계산 가능한 문제로 전환하고 이로부터 실용적인 알고리즘을 제안하는 과정이 ‘아름답다’고 밖에는 말할 수 없는 흥미로운 토픽이었습니다.
Value function을 approximation해서 optimal policy를 찾아내는 접근과 달리, parametrized policy를 정의하고, parameter에 대한 policy performance의 gradient를 통해 optimal policy를 직접 찾아내는 방법입니다.
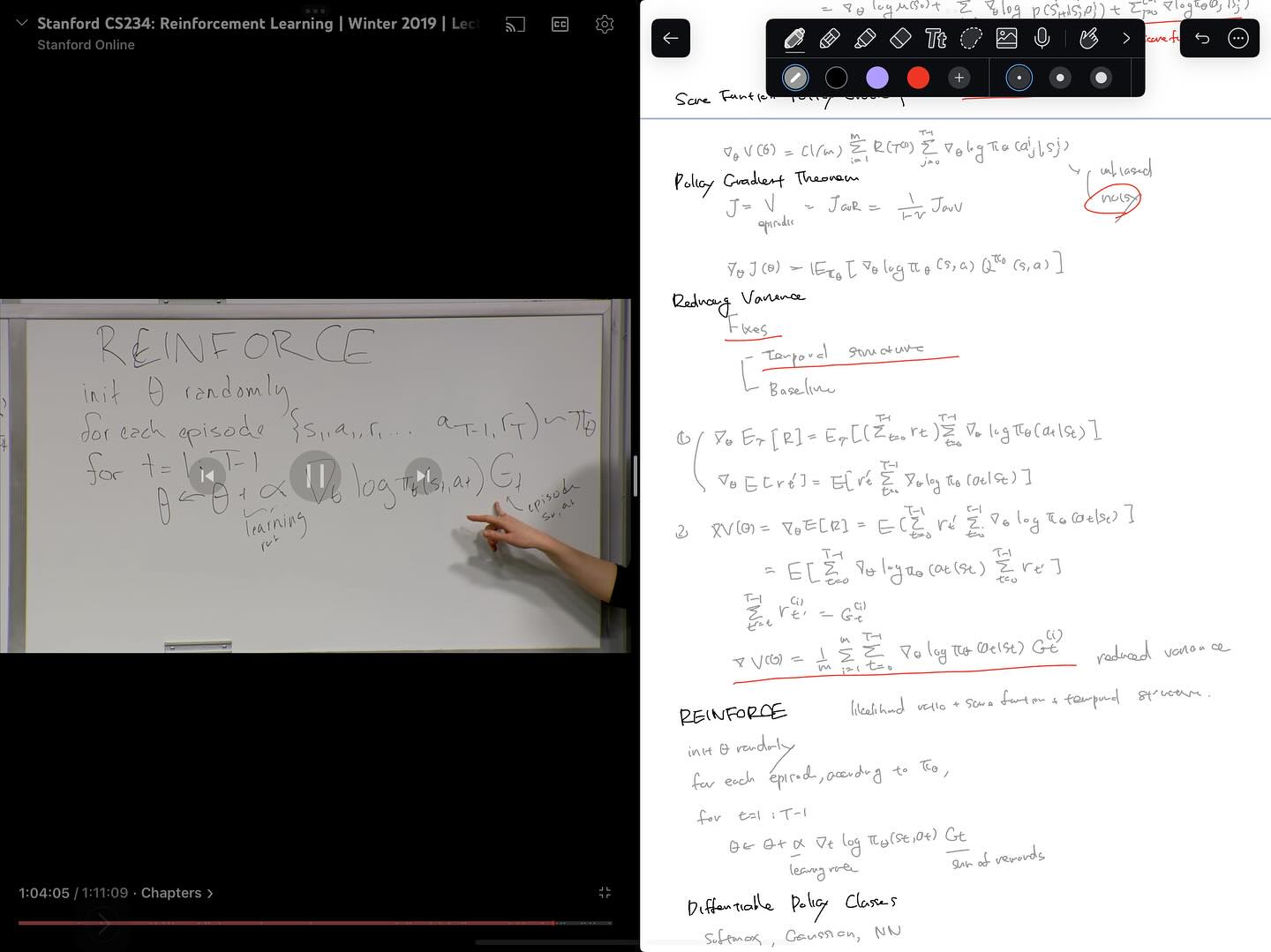
Policy Gradient Theorem에 기초해서 REINFORCE라는 알고리즘을 얻는 과정을 설명하고, variance를 줄이기 위해 baseline을 도입한 REINFORCE 알고리즘을 얻는 과정도 배울 수 있었습니다.
이어서 Actor-Critic method도 소개하는데 REINFORCE with baseline 알고리즘에서 baseline으로 state-value function을 사용해서 action의 결과를 평가하기 위한 기준 역할을 합니다. state-value function은 semi-gradient TD를 통해서 학습하고, REINFORCE 알고리즘에 자연스럽게 통합될 수 있습니다.
Policy Gradient Method들은 stochastic한 policy를 자연스럽게 학습할 수 있고, exploration을 얼마나 할지도 학습할 수 있는 장점이 있습니다. 또한, action space가 연속적일 때도 적용할 수 있습니다.
이 책에서 다루는 전통적인 RL 방법들에 대해서는 어느 정도 기초가 마련된 것 같고, 당장은 CS234 강의를 마저 듣고, 그 다음에는 Deep Reinforcement Learning 방법을 공부하기 위한 책으로 넘어가볼까 합니다.
올해의 방향성을 논의하면서 여러가지 사업 기회나 제품의 방향성에 관한 아이디어들이 다루어진다. 어떤 것들은 새로운 것이 아니고 오랫동안 논의되어오고 그동안 중요하게 고려되어온 것들도 있다. 하나하나의 아이디어들을 보면 모두 좋은 기회들과 고객에게 전할 수 있는 가치들이 숨어있다.
이어서 얼마나 많은 자원이 투입되어야 하는가, 이를 둘러싼 비즈니스 환경이 어떠한가, 마일스톤 내에 가능한가와 같은 의견들이 개진된다. 물론, 여러가지 어려움이 있지만, 그러한 어려움을 헤쳐나간다는 가정 하에 어떤 것들은 실행가능해보인다. 어떤 것들은 그렇지 않다. 추가적인 투자가 필요하거나, 마일스톤 내에 성공이라고 부를만한 충분한 진척을 내기 어렵거나, 결코 녹록치 않은 경쟁 환경인 경우들이다.
그러한 기준들을 통과한 아이디어들에 대해서, 마지막으로 매우 구체적인 숫자로 표현된 회사 목표를 달성할 수 있는지를 검토한다. 여기서 많은 아이디어들은 ‘불확실’하다. 아마 누구라고 하더라도, 어떠한 사업이나 제품 방향성이 완벽하게 실행이 되었을 때, 100%의 확률로 구체적인 기한 내에 구체적인 매출이나 이익을 낼 수 있을거라고 장담하기 어렵다. 실은 50%의 확률로 그러하다고 장담하는 것도 쉽지는 않다.
자리로 돌아와서 모호하게 표현된 가능성에 대한 의견들을 수치화할 수 있는 방법에 대해서 생각한다. 구체적인 숫자로 표현된 회사 목표에 대해 잠시 눈을 감을 수는 없는가 생각을 한다. 좋은 아이디어들은 많이 있다. 분명히 회사의 가치에도 제품의 품질이나 고객의 만족에도 도움이 될 것이다. 구체적인 숫자는 잠시 무시하고 가장 커다란 가치를 줄 수 있는 것에 ‘도전’할 수는 없나 생각을 한다. 하지만, 곧이어 짧은 기간의 성공 가능성도 확신할 수 없다면, 어떻게 장기적인 성공 가능성에 주어진 자원을 모두 투자할 수 있는지, 또한 장기에 걸친 실행 자체도 구체적으로 표현된 마일스톤 없이는 위태로운 것이 아닌가 하는 생각으로 이어진다.
어렵다. 아마도 모든 회사의 대부분의 사업 기회들과 제품 아이디어들은 그러할 것이다. 기회들과 아이디어들은 대개 제어할 수 없는 요인들과 불확실성을 가지고 있다. 훌륭한 아이디어처럼 보이는 것들에 대해서 얘기하는 것도 그에 대해서 동의하는 것도 쉬운 일이다. 하지만, 실제로 그 훌륭하다고 말하는 아이디어에 가장 중요한 무언가를 걸고 헌신하는 것은 완전히 다른 문제이고 어려운 일이다.
그러한 불확실성 속에서 가장 좋은 결정을 할 수 있는 능력 만큼이나 용기도 중요한 것 같다. 어쩌면 그 둘은 같은 것일지도 모른다.
Reinforcement Learning 7, 8강을 들었습니다. 각각 Imitation Learning과 Policy Search의 도입부를 다루고 있습니다.
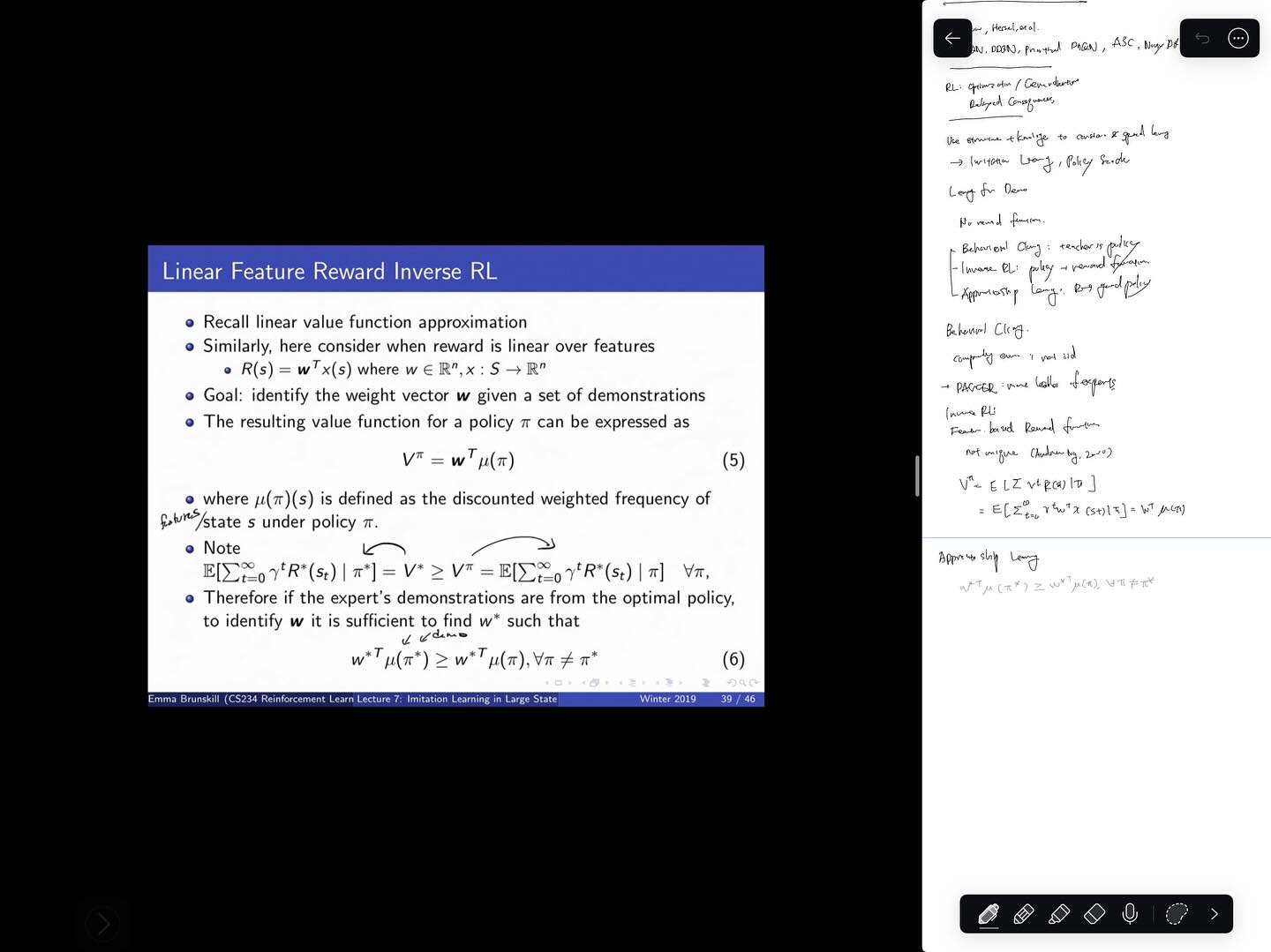
Imitation Learning은 전문가의 시연로부터 어떻게 모방할 수 있는가의 문제를, 전문가의 state, action 샘플로부터 reward function을 추정하거나 이로부터 optimal policy를 학습함으로써 풀고 있습니다.
그동안 value function을 학습해서 policy evaluation 및 control을 해왔던 value-based method를 다뤄왔습니다만, 8강에서는 policy 자체를 학습하는 접근을 다루기 시작합니다. policy 자체를 파라미터를 이용해 표현하고, policy의 value를 최대화하는 파라미터를 찾는 최적화 문제로 다룹니다. 최적화 방법에는 여러가지가 있지만, Likelihood Ratio / Score Function Policy Gradient에 temporal structure를 도입함으로써 결국 잘 알려진 REINFORCE 알고리즘을 얻게 되는 과정을 설명합니다.
다음 강의들을 듣는 동시에, Intro to Reinforce Learning의 Chapter 13도 함께 읽어볼 예정입니다.
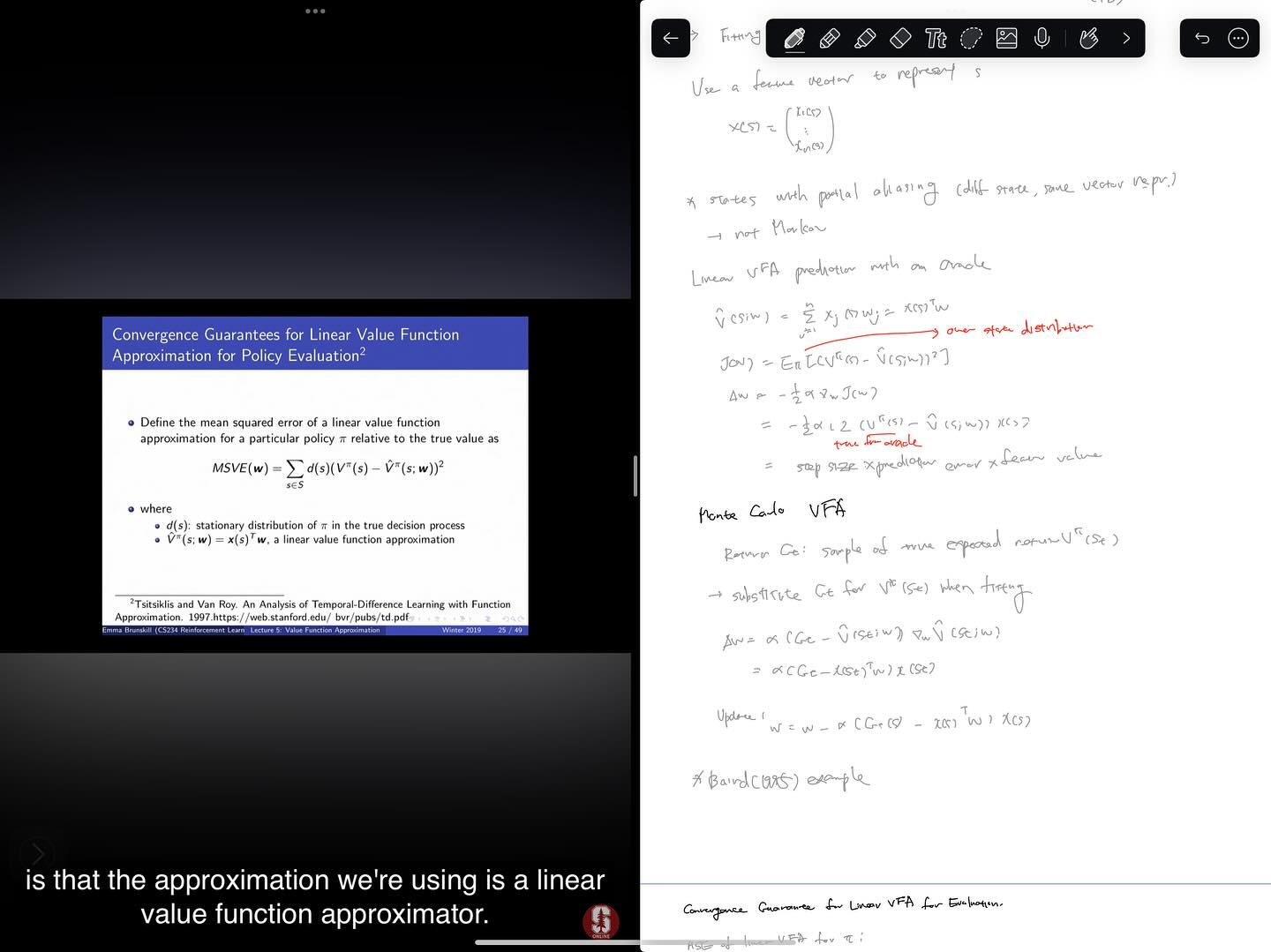
Chapter 9 On-policy Prediction with Approximation을 읽었습니다.
state space가 매우 크고 이에 따르는 데이터가 큰 문제에 대해 샘플로부터 value function을 approximation하는 문제로 넘어가게 됩니다. state를 대표하는 feature들로부터 value를 계산할 수 있는 function의 weight를 샘플들을 통해서 찾는 supervised learning 문제로 바라봅니다.
여기서부터는 SGD라든가 여러 basis function들을 기반으로 하는 linear method들, non-linear method로서의 neural network 등의 일반적인 방법들이지만 그동안의 RL 연구에서 자주 활용된 방법들을 소개하고 있는 것 같습니다. 이 과정에서 convergence 문제라든가 dimensionality reduction에 관련한 이슈도 다루고 있습니다. coarse coding이나 tile coding 등은 처음 들어본 것이라서 살짝 흥미로웠습니다. 현재는 deep learning이 트렌드가 되었기 때문에 긴장감이 좀 떨어지지만, 그래도 기존의 접근들을 기반으로 새로운 접근들을 쌓아올라가는 면들이 현재도 있는 것 같아서 도움이 될 수도 있겠다는 생각 정도는 들었습니다.
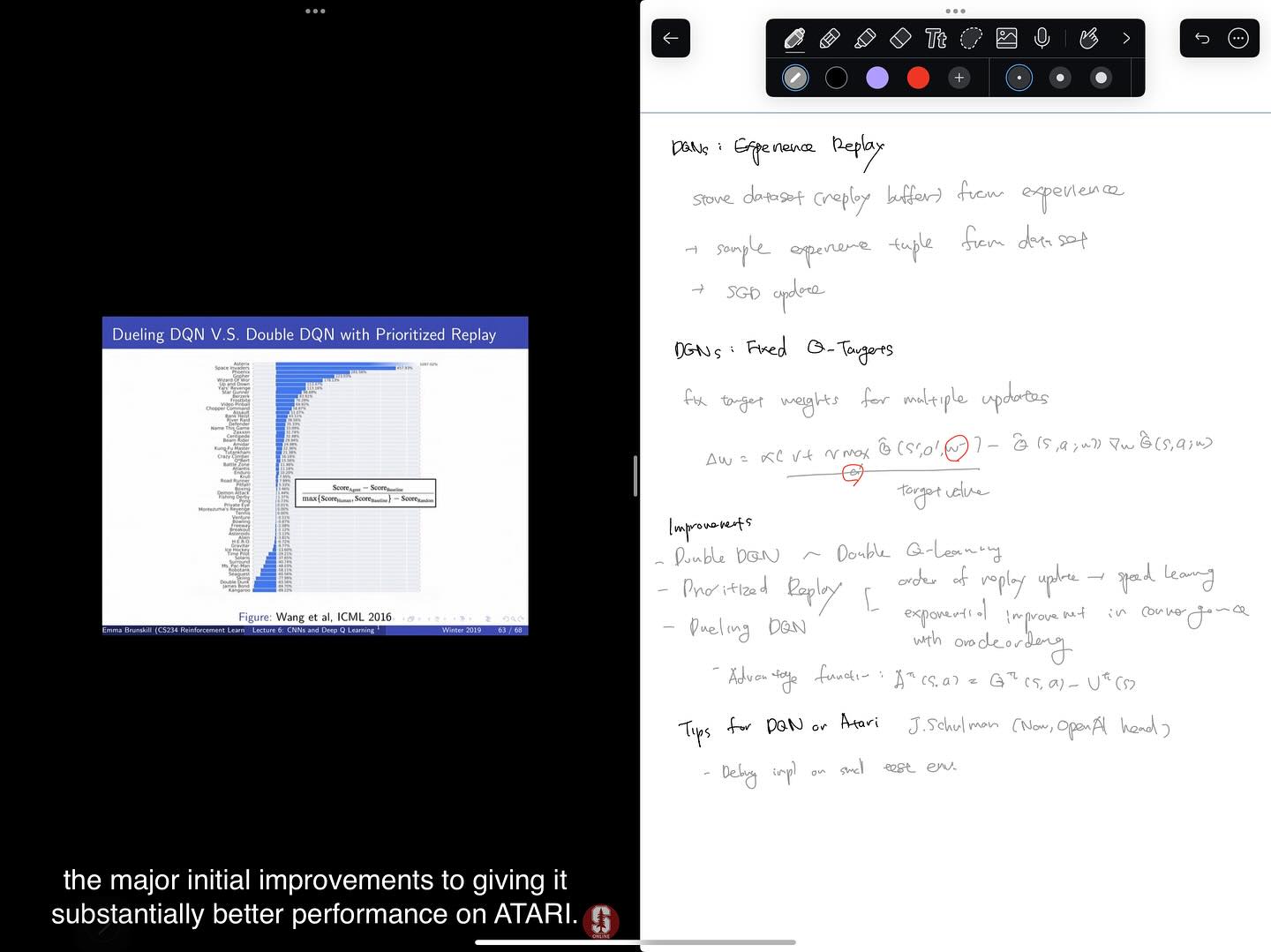
CS234 Reinforcement Learning 강의 6강까지 들었습니다. function approximation으로 넘어갔고, 아타리 게임을 플레이하는 것으로 화제가 되었던 DeepMind의 DQN까지 배웠습니다. function approximation + off-policy에서의 convergence 문제 때문에 관심이 시들하다가 DQN 때문에 다시 많은 관심을 얻게된 것 같네요. 그나저나 TRPO와 PPO의 주저자인 J. Schulman이 OpenAI의 cofounder인 것도 이 강의를 통해 알게 되었네요.
IMAX 극장 갈만한 시간을 찾다가 차라리 그만한 작품이라면 두번 볼 요량으로, 동네 극장 심야상영을 저렴하게 보고 왔다. 아내가 여행간터라 휴가를 쓴 터라 평일이지만 마음 편하게 다녀올 수 있었다.
듄 시리즈가 예지력과 정신훈련, 인간 컴퓨터와 같은 소재를 사용하는 소설이다보니, 원작에는 내적 대사가 상당히 많은데, 이를 드러내기 위해서 내적 대사를 다른 인물이 말하도록 한 장면들이 많이 보였다. 원작을 읽지 않은 관객들이 대부분일 것을 감안하면 전반적으로는 나쁘지 않았다고 생각한다. 다만, 이로 인해 가장 많은 영향을 받은 것은 폴의 의지에 대한 챠니의 입장을 반동으로 설정한 것 같아서 마음에 많이 걸렸다. 조금 더 입체적인 인물로 만들기 위한 각색 정도로 볼 수는 있을 것 같다. 또한, 1편에서와 마찬가지로 제시카의 영향력이 많이 축소된 점도 계속 마음에 걸렸다. 내 기억이 맞다면 폴의 여동생 알리아를 대변하는 것 같은 장면은 없었던 것 같은데 줄곧 대변자 정도로만 행동한 것 같아서 아쉬웠다.
원작에 대비한 인물들의 중요한 변화에도 불구하고 원작의 세계관과 이어지는 상당히 많은 부분들 – 정치적인 이해 관계와 생존을 위한 프레멘의 문화, 생명의 물에 관련한 요소 – 을 한정된 시간 안에 이토록 자연스럽게 넣을 수 있었던 것은 칭찬받아 마땅하다고 생각한다.
듄 1권의 후반에 해당하는 영화이기 때문에 대단원에 해당하는 전투와 결투, 검투사 시합 등이 들어갔다. 영화를 보기 전에도 영화로 만들었을 때도 대중들을 만족시키기 좋은 요소라고 생각했다. 대규모 전투도 멋있는 비주얼의 장비들과 웅장한 음악, 있음직한 전개로 상당히 만족스럽게 그려졌다.
인물들의 모습들에서 의외였던 것 중 하나는 페이트 로타였다. 소설 속에서는 준수한 외모이지만 잔인한 성격을 가진 인물이지만 영화에서는 하코넨의 주요 인물들과 대중들은 모두 대머리..로 잔인한 성격을 외모에 반영함과 동시에 전체주의적인 하코넨 사회의 모습을 간명하게 그리려고 한 것 같다.
반대 의미로 의외였던 것은 비중이 높아진 이룰란 공주의 복장들이 많은 공을 들인 것처럼 참 아름다웠다는 것이다. 듄의 메시아에서는 이룰란 공주의 역할이 좀 더 늘어나는 만큼 후속 작품도 만들어지면 참 좋겠다는 생각을 했다.
원작에서 폴은 자신이 예지하고 선택한 미래에 대해 회의와 책임, 결심을 반복하는데 누구에게도 떠넘길 수 없는 무앗딥만의 고뇌로 그려진다. 그러한 고통 하에서도 지속적으로 위안으로 삼는 곳은 챠니에 대한 사랑이었다. 그렇기에 챠니와의 사랑이 싹트는 장면에서 폴이 챠니의 다른 이름인 “시하야”를 부르는 순간 눈시울이 붉어졌다.
유튜브에 공개되어있는 2019년 겨울의 CS234 Reinforcement Learning 강의 4강까지 들었습니다. 3강을 듣다가 이해하기가 좀 어려워서 RL: An Introduction (Sutton and Barto)의 관련 chapter들을 먼저 읽고나니 강의를 훨씬 편하게 들을 수 있었습니다.