관심 가는 소프트웨어 북클럽이 종종 있다. 그런데 대부분 미국 중심이다 보니, 주기적으로 모이는 시간대가 보통 새벽이다. 그래서 참여하기가 힘들고, 참여를 못 하면 북클럽의 의미도 없어진다. 그런데 최근에 Software Internal 관련 이메일 북클럽이 있다는 소식을 듣고, 기대가 되어 바로 참여해보기로 했다. 책은 Edward Sciore의 Database Design and Implementation. 잘 모르는 책이지만, Software Internal 북클럽이니 믿고 일단 신청하고 주문부터 했다.
이메일 북클럽 운영 방식은, 참가자들이 Google Group에 가입해 매주 정해진 디스커션 리더가 새 챕터별로 쓰레드를 여는 형태였다. 특별히 큰 의무감이 따르지 않는 방식이었는데도, 매주 열리는 디스커션이 일종의 페이스메이커 역할을 해주었다.
요즘 공부 의욕이 높지 않아서 많은 시간을 들인 것은 아니고, 주로 퇴근길 버스에서 틈틈이 읽고 있다.
Chapter 1, 2, 3이 각각 Database Systems, JDBC, Disk and File Management 주제를 다루는데, 학부 수준의 내용이라 흥미가 생기지 않아 괜히 시작했나 싶기도 했다. Software Internal 북클럽인데 왜 하필 이 책을 고른 건지 의문이 들었다.
그러나 Chapter 3 마지막에 이 책의 가치를 조금 이해하게 되었다. 이 책은 Java로 만든 매우 단순한 데이터베이스 구현체인 SimpleDB를 함께 설명하면서, 각 장 마지막에 코드 레벨로 개념을 다룬다. Excercise에는 이 코드를 개선해보는 과제들도 있다.
어제 퇴근길에 Chapter 4 Buffer Management까지 읽었다. 데이터베이스의 핵심 구조이다 보니 집중해서 읽게 되었고, 코드까지 함께 다뤄볼 수 있어 흥미로웠다. 아침에 시간을 내어 오래된 SimpleDB 코드를 빌드하고 실행할 수 있게 만들었다.
처음 시도해보는 소프트웨어 북클럽이라 약간 망설임도 있었지만, 시간이 갈수록 생각보다 많은 것을 배우고 있다. 단순히 읽기만 하는 것과 달리, 직접 코드를 만져보며 책 속 개념들이 어떻게 구현되는지 더 깊이 이해하게 된다. 이제는 다른 언어로 포팅해보는 것도 하나의 도전으로 삼고, 앞으로도 꾸준히 참여해보려고 한다.
내 삶에 영향을 미칠만한 중요한 뉴스는 어차피 지인들을 통해서 듣게 된다. 그 중에서도 매우 급박한 소식은 트위터를 통해서 듣는 것이 훨씬 빠르다. 모두를 위한 뉴스가 꼭 나에게 유익한 것은 아니다. 뉴스 기사들은 사건사고라든가 내가 응원하는 정당이나 스포츠팀의 패배와 같이, 오히려 불안감이나 스트레스를 주는 경우도 많다. 그래서 예전에는 뉴스 소비를 최소화하려고 노력하고, 또 지인들도 설득하기도 했다.
하지만, 언젠가부터 아침에 일어나자마자 정치적인 뉴스 영상을 보는 게 습관이 되어버렸다. 지난 총선 무렵이었던 것 같은데, 정확히는 기억나지 않는다. 정치 현안과 논점들에 대해서 이해하는 것도 재미가 있다. 이렇게 30분에서 1시간 정도 뉴스 영상으로 하루를 시작하는 게 자연스러워졌고, 인과관계는 불확실하지만, 그 후로 공부를 포함한 다른 생활 습관까지 느슨해진 것 같다.
이런 나 자신을 인지하고 기억을 되돌아보니, 아침에 30분에서 1시간 정도는 내가 하고 싶은 일들을 하는 것으로 루틴을 만들고 실행한 적이 있었다. 예를 들어, 아침 공부를 하거나 가벼운 근력 운동을 하거나, 아니면 조용히 명상을 하기도 했다. 오늘부터 다시 뉴스 없는 아침을 시작한다. 1일차, 그리고 앞으로 계속.
작년 즈음 광고 네트워크의 문제와도 맞닿아있어서 게임이론을 공부하는데에 흥미가 생겼었는데, 냉전체제에 어떻게 적용되었다는 것인지 구체적인 사례가 있으면 좋겠다고 생각하던 차에 2차 포에니 전쟁을 Core나 Shapley Value와 같은 개념으로 설명하는 책을 읽게되어어서 즐겁다. Shapley Value는 SHAP 관련해서 들어본 적이 있었지만 원래 이러한 개념인지는 처음 제대로 알게되었다.
Byrne Hobart의 뉴스레터에서 Invisible Efficiencies라는 흥미로운 글을 읽었다.
AI 시대가 되었지만, 그러한 성과가 GDP와 같은 경제지표로 나타나지 않는다는 기사가 간혹 보이곤 한다. 이 글에서는 기술을 통한 높아진 효율이 왜 측정되지 않을 수 있는지에 대해서 다루고 있다.
더 나은 진통제가 발명되었다면, 실제로 많은 사람들은 이를 통해서 생산성이 높아지겠지만, 그 결과는 노동 공급의 증가로 관찰될 것이고, 석유를 발견하는 효율적인 방법이 개발되었다면, 이것은 석유 공급량의 증가로 보일 것이라는 예시를 인용하고 있다. 즉, 실제로 효율성을 높이는 어떤 기술이 도입되었다고 하더라도, 그 결과는 효율성의 증가처럼 보이는 것이 아니라 (다른 요인에 의해서 영향 받을 수 있어서 마치 기술의 영향처럼 보이지 않을 수도 있는) 어떤 양의 증감으로 해석될 수 있다는 것이다. 결과적으로는 그 기술의 효율성은 보이지 않게 되는 것이다.
Let’s say someone invents a useful painkiller, and that makes it easier for many people to show up to work and be productive. Output will rise, yet that advance will show up as an increase in labor supply, rather than as an increase in technology or scientific knowledge. Similarly, a new method for discovering oil may boost output, but that will be classified as an increase in oil supply, even though it does properly represent a form of scientific progress.
기술 기업들에 관한 예시도 들고 있는데, Uber나 DoorDash는 원래라면 활용하기 어려운 노동력으로부터 가치를 생산하지만, 이는 노동 공급의 증가로 관찰된다. 또한 이러한 비즈니스의 결과로 발생하는 경제활동들이 있지만, 실제로 소비자의 효율성 증가 – 더욱 적은 시간을 운전하는 것 – 는 경제 관점에서 측정되지 않기 때문에, 생산성의 증가로는 관찰되지 않는다.
There are some companies whose economic impact is that they’ve unlocked a previously inaccessible cohort of workers. Uber and DoorDash have made it so that someone who can work in increments of a few hours at a time, with an unusual and inconsistent schedule, can still earn money. […] […] To the extent that users of these products are using some of their extra time to work, and are earning enough to justify it, there might be a marginal productivity impact. But again, it’s showing up in the wrong place: higher labor input gets measured, but less time spent driving to and from Chipotle in your own car is not part of measured economic output, so it won’t show up in productivity per hour. None of this is truly a problem with GDP, since GDP does a surprisingly good job of what it’s trying to measure. But what it’s really trying to measure is the scope of the taxable economy; it’s impractical to assess a sales tax on the markup in value between a home-cooked meal and its ingredients. […]
따라서, 이 글에서는 효율성을 개선하는 기술에 의한 거시적인 생산성 향상의 증거를 찾으려고 할 때는 단순히 데이터를 보는 것이 아니라, 오히려 각각의 사안을 자세히 들여다봐야 한다고 결론짓고 있다. 만약 제품이 편리하고 누군가가 그 제품을 통해서 – 생산성 향상분의 일부에 해당한다고 생각할 수 있는 – 돈을 벌고 있는 동시에, 모두가 이익을 얻고 있는 상황이라면, 데이터로 관찰이 되지 않더라도 생산성 향상이 있다고 판단할 수 있다는 아이디어를 제시하고 있다.
[…] So if you’re looking for broad-based productivity gains from the deployment of efficiency-improving technologies, focus on anecdotes over data: if the product is convenient, and someone’s making money from it, then there are two possibilities: either it’s unsustainable because one or more participants are getting a bad deal, or it’s a productivity gain in disguise.
이 글은 경제적인 데이터나 지표의 한계에 대해서 논하고 있지만, 좀 더 일반화를 해 볼 여지는 있는 것 같다. 효율성 개선에 따른 생산성 향상을 찾으려고 할 때, 깊은 고민 없이 거시적인 데이터나 기준을 사용하는 경우가 있을 수 있다. 그러한 데이터나 기준에 실질적인 효율의 개선이 포함되지 않을 수 있다는 가능성을 항상 유념해야 한다. 그러한 경우에는 효율의 개선이 실제로 존재하는지 개별 사안을 분석해보되, 이를 다시 데이터나 기준에 포함시킬 수 있는 방법을 고민하는 과정이 필요해 보인다.
1. LLM에 컴퓨팅과 데이터를 때려넣으면 성능이 올라가는 것에 대해 한계효용 체감이 있을 것이라는 얘기는 계속 있어왔고, 그러한 경쟁조차도 치열한 접전이 되었다. 이번에 GPT-4o의 초점이 달라진 것을 보면 그러한 상황을 반영한 것이 아닌가 싶기도 하다. (이러고나서 GPT-5가 짜잔하고 나올 수도 있지만…)
2. Auto-Regressive LM의 본질 상 planning과 reasoning에 한계로 인해 현재의 기술만으로 singularity는 달성되지 않을 듯하다.
3. 치열한 경쟁으로 인해 LLM weights와 fine tuning 도구들은 commodity가 되었다.
4. 현재 ChatGPT 등은 스마트한 information retrieval 도구이고 엔터프라이즈에서 이러한 일을 대신 해주는 회사들도 많다.
5. 우리의 일을 최소한의 관여로 대신해주는 것에 관한 것은 아직 충분한 성과가 보이지 않는 것 같다.
이러한 상황으로 볼 때는 특정한 영역에 대해 autonomous agent를 구축하는 것에 대해 좀 더 많은 투자가 이루어져야 할 것 같다. 현재의 LLM capability와 실제 세상과 연결하기 위한 복잡다단한 엔지니어링, 요소마다 최적화하기 위한 모델들을 조합하고 제품 다듬기에 충분한 노력을 기울이면, 어떤 영역의 일반 작업들에서는 충분한 매력이 있는 제품을 얻을 수 있을 것 같다.
물론 이러한 생각을 하는 사람들(예를 들어 Andrew Ng의 agentic workflow)과 스타트업들(코딩을 완전 자동화했다는 주장..)은 이미 엄청나게 많을 것으로 예상된다.
이러한 소프트웨어를 빌드해서 실제로 돈을 벌 수 있을지에 대해서는 굉장히 의문스럽고, 아마도 실패할 수도 있고 매우 힘들겠지만, 그래도 빌드하는 과정은 인생을 한번 걸어보고 싶을 정도로 재미있을 것 같기는 하다.
15강에서는 High-confidence Off-Policy Evaluation이라는 (아마도 교수님의 연구실에서 다뤘던 토픽인) 최근의 연구 결과를 다루고 있는데, 대략 새로운 policy의 expected return의 lower confidence bound를 계산함으로써 monotonic improvement를 일정 수준으로 보장하는 학습의 안전성을 얻기 위한 방법이라고 볼 수 있을 것 같습니다. 기초를 배우는 입장이라서 대충 이런게 있구나 하고 넘어갔습니다.
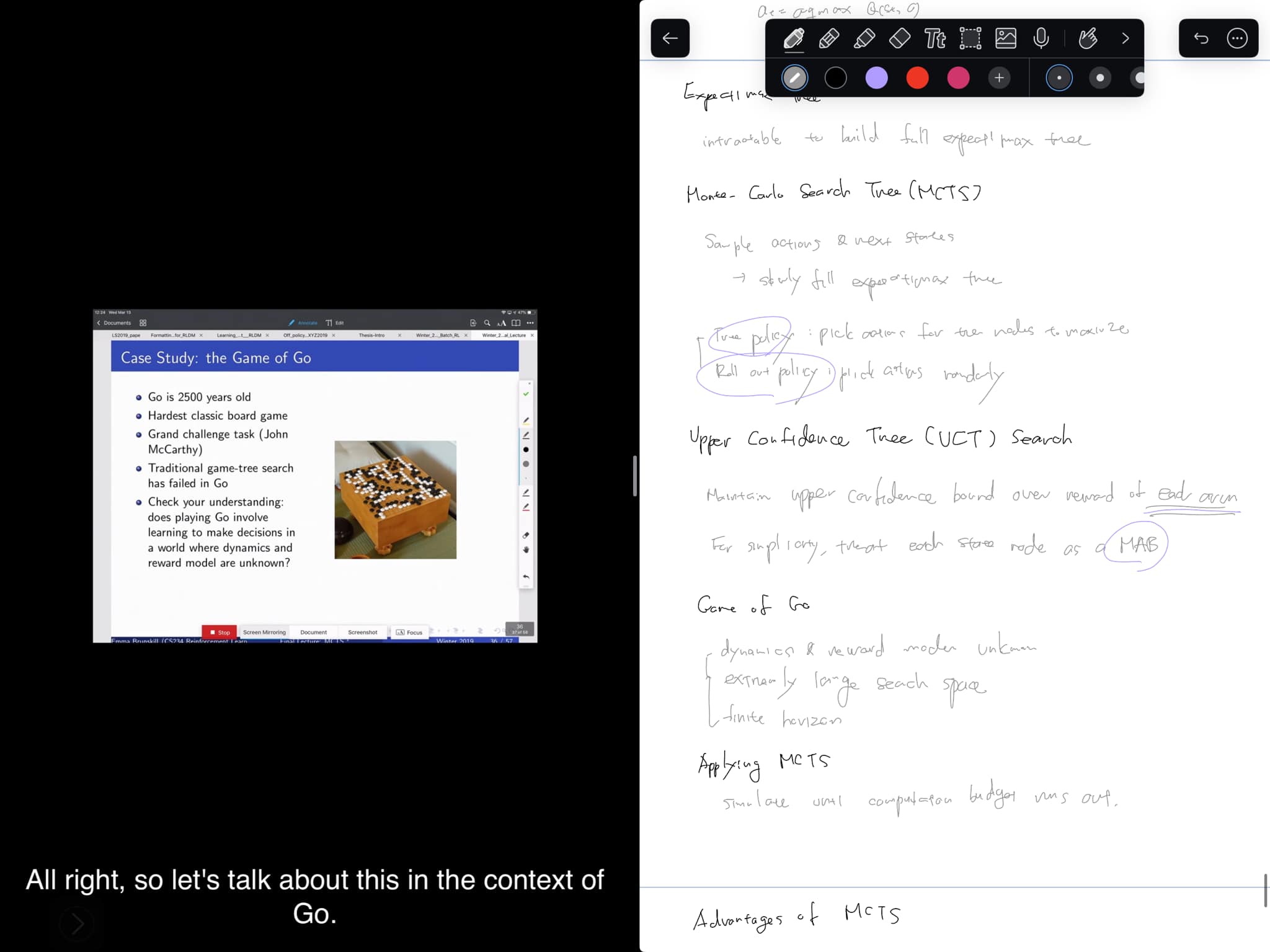
16강에서는 Monte-Carlo Search Tree에 대해 다루고 있습니다. 우리가 흔히 알고 있는 게임 트리와는 달리, 전체 스페이스를 탐색하는 것이 아니라, 일정 수의 시뮬레이션만을 수행하고, 일부 트리에 해당하는 이 데이터를 기반으로 결정을 내립니다. 또한, UCB1과 마찬가지로, upper confidence bound를 적용해 액션을 결정하여 exploration/exploitation을 수행합니다 (UCT). 결과적으로는 마치 UCB1이 적용된 MAB를 각 node마다 실행하는 느낌입니다. MCTS는 이 이름을 가지기 전부터 바둑에서의 강력함을 증명해오다가 DNN을 접목한 AlphaGo에까지 적용되었습니다. MCTS의 주요 페이퍼들과 AlphaGo에 관련한 페이퍼들을 읽어볼 생각입니다.
이로서 1월 중순 무렵에 시작했던 CS234 Reinforcement Learning 강의와 이에 관련한 Sutton & Barto 책을 통한 공부를 마쳤습니다. 주요 RL 알고리즘을 구현해보는 동시에, 공부를 시작할 때 사둔 Foundations of Deep Reinforcement Learning을 읽어볼 생각인데, 효과적인 학습을 위해 다른 토픽으로 1-2달 정도 넘어갔다가 진행해 볼 생각입니다.
누군가나 주어진 상황 때문에 상처를 받았다고 피해를 입었다고 그 생각에 사로잡혀 있기에는 인생은 너무 짧다. 설령 상처나 피해를 입었다고 하더라도 거기에 계속 머물게 하는 것은 내 생각 때문이다. 그런 생각을 의도적으로 버리려고 노력한다면 하루라도 아까운 삶을 좀 더 의미있게 누리는데에 도움이 될 것이다.
우선 MDP에 비해 상대적으로 단순한 multi-armed bandits 문제와 regret과 같은 framework의 formulation으로 시작합니다.
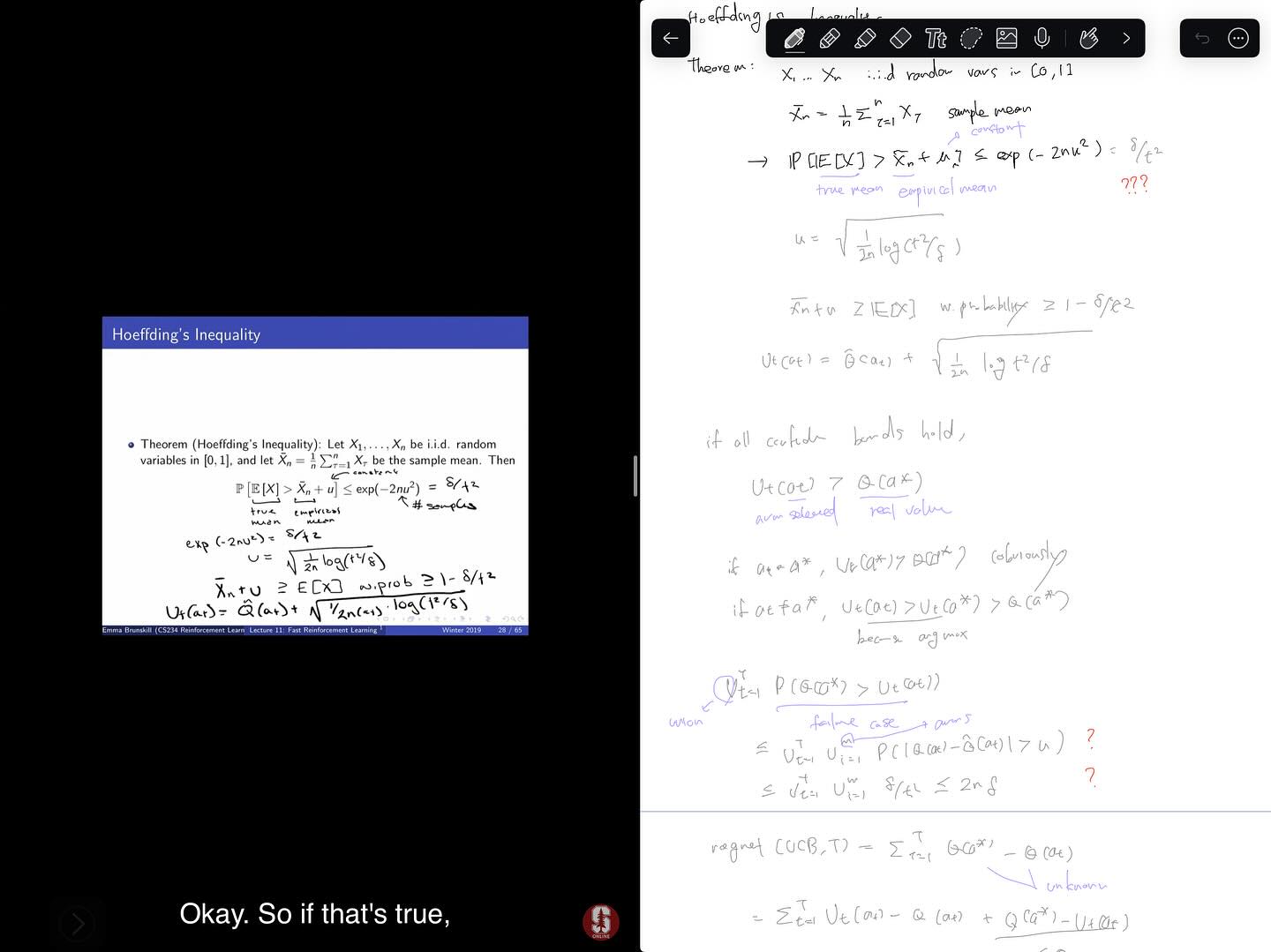
이어서, 불확실한 상황에서 탐색을 통한 정보를 얻는 것의 가치를 높게 보는 Optimism in the face of Uncertainty 원리로부터 UCB1 알고리즘을 설명합니다. UCB 알고리즘들은 여러 경로로 접해왔지만, 이러한 원리 하에서 이해하게 된 것은 처음입니다. 또한, 각 arm들을 확률변수로 보고 Hoeffding’s Inequality를 통해 모르는 정보들을 제거하고 UCB1 알고리즘을 유도하는 과정도 꽤 흥미로웠습니다.
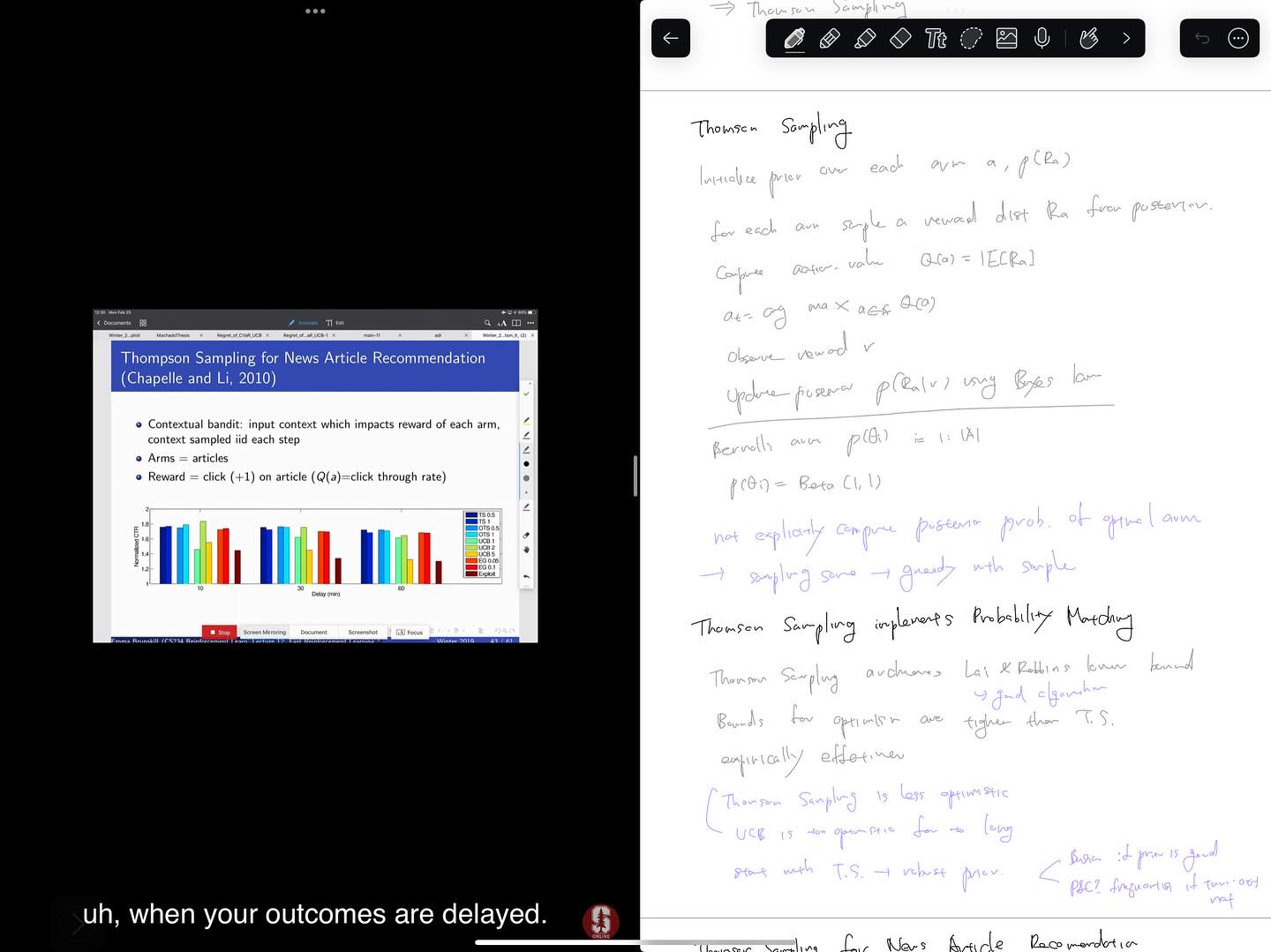
다음으로 reward distribution에 대해 Bayesian inference를 이용하는 Bayesian Bandits을 배우게 됩니다. Bayesian inference는 분석적으로 계산하기 까다로운데 conjugate prior를 통해서 이를 가능하게 하는 것도 처음으로 알게되었습니다. Bayesian bandits 하에서 Probability matching 접근을 하는 대표적인 알고리즘으로 Thomson Sampling이 다루어집니다. Thomson Sampling 알고리즘에서는 posterior로부터 sampling을 하고 이에 기반해 action을 결정하고, 이에 따른 reward를 다시 posterior에 반영하는 단순한 휴리스틱으로 되어있는데, 경험적으로 매우 잘 동작한다고 하네요.
마지막으로 PAC (Probably Approximately Correct) 개념과 이에 해당하는 알고리즘을 배웁니다. Supervised Learning에서와 비슷하게, 일정 이상의 확률로 optimal value로부터 일정 이하의 차이가 보장되는 것을 말합니다. 이러한 알고리즘의 예로 MBIE-EB를 들고 있고 어떤 RL 알고리즘이 PAC을 만족하기 위한 조건들도 다룹니다.
이번에는 강의도 쉽지 않았고 Bayesian Inference에 대해 정확하게 이해하기 위해 별도로 공부를 해야만 했습니다. exploration 방법들을 MDP에 적용하는 내용도 있었지만 이번에는 skip했습니다. 이번에 배운 내용들을 Bandit Algorithms 책과 인터넷에서 다시 한번 복습을 해보고 나머지 강의들을 들을 예정입니다.